PaddlePaddle论文复现:TPN
0
收藏
最后编辑于2022-04
Temporal Pyramid Network for Action Recognition(TPN)
论文复现营课程链接:https://aistudio.baidu.com/aistudio/education/group/info/1340
1. Idea
- 视频中动作的速度反映出动作的动态信息和时间尺度的特征
- previous work: 以一系列不同的sample rate从视频中采样,形成input-level frame pyramid,每个level的input会输入到不同的backbone中进行特征提取,最后融合多个分支的输出获得最终预测结果,但这种方式计算量较大
- 视频识别中的一些常见的模型,如C3D、I3D等,由一系列temporal conv堆叠而成,在这些网络中,随着深度的增加,其时间尺度的感受野逐渐增大。所以,在一个single model上不同特征层已经采样到了fast-tempo和slow-tempo的信息。
- TPN使用一个固定的rate从视频中采样,输入到网络中,从不同的feature map中采样,得到包含不同visual tempo的输入
2. Feature Source
-
Collection of Hierarchical Features
- Single-depth pyramid:从某个depth的特征图F(C x T x W x H)上采样,采集的feature size相同,方便后续的feature fusion处理,但是这种方法采集的feature只包含此深度特征图上的视频语义信息。
- Multi-depth pyramid:在不同深度的特征图上采样。这样采集的feature包含更丰富的语义特征。
-
Spatial Semantic Modulation:为在空间尺度上对齐通过Multi-depth pyramid采样得到的feature,除了最顶层的feature,对其余feature进行一系列不同步长的卷积操作,使其spatial shape与顶层feature一致。同时,为得到更健壮的语义信息,为每一层加入一个额外的分类头,这里使用Cross Entropy Loss
-
Temporal Rate Modulation:引入超参,对feature进行时间维度的下采样,进行时间维度的对齐
3. Information Flow of TPN
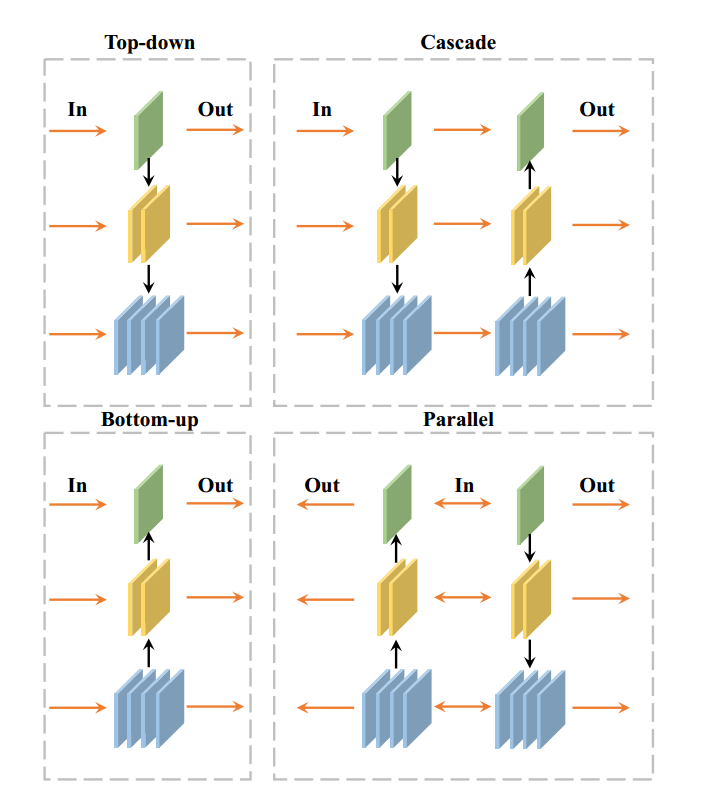
- 黑色箭头代表feature聚合方向
- 橙色箭头代表输入、输出方向
4. Implementation
-
网络结构
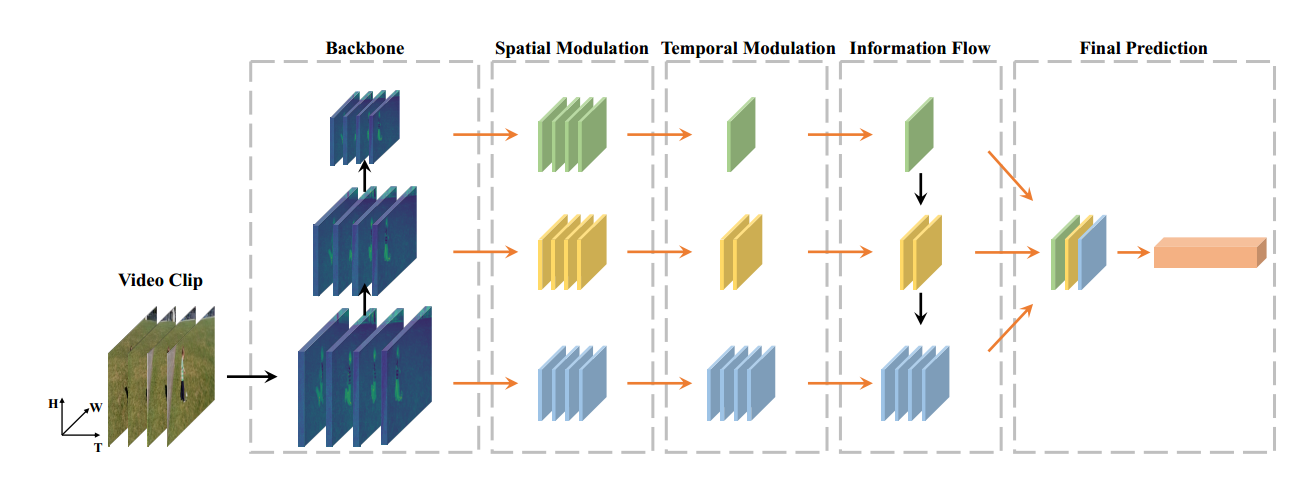
-
inflated ResNet 作为3D backbone,original ResNet 作为2D backbone,在res2,res3,res4,res5特征层上采样feature,其下采样倍数分别为4,8,16,32。
-
在spatial semantic modulation中,使用一系列不同步长的卷积使其channel变为1024
-
在temporal rate modulation中,使用一个卷积和一个最大池化
-
最终,通过information flow结构,每个特征通过最大池化rescale,最终concatenate,输入到fc层中进行最终预测
收藏
点赞
0
个赞
请登录后评论
TOP
切换版块
学习一下