
运行报cuda 916错误
下面是weight (attention map)& g 算 最终值算子
.cu 文件
#include "paddle/extension.h"
template
__global__ void initout(data_t *out, const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int plane = blockIdx.z;
if (x < width && y < height && plane < chn) {
for (int batch = 0; batch < num; ++batch) {
out[(batch * chn + plane) * sp + y*width + x]=(data_t)0.0;
}
}
}
template
__global__ void ca_map_forward_kernel(const data_t *weight, const data_t *g, data_t *out, const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int plane = blockIdx.z;
if (x < width && y < height && plane < chn) {
for (int batch = 0; batch < num; ++batch) {
//out[(batch * chn + plane) * sp + y*width + x]=(data_t)0.0;
for (int i = 0; i < width; ++i) {
data_t _g = g[(batch * chn + plane) * sp + y*width + i];
data_t _w = weight[(batch * len + i) * sp + y*width + x];
out[(batch * chn + plane) * sp + y*width + x] += _g * _w;
}
for (int i = 0; i < height; ++i) {
if (i == y) continue;
int j = i
data_t _g = g[(batch * chn + plane) * sp + i*width + x];
data_t _w = weight[(batch * len + width + j) * sp + y*width + x];
out[(batch * chn + plane) * sp + y*width + x] += _g * _w;
}
}
}
}
template
__global__ void ca_map_backward_kernel_w(const data_t *dout, const data_t *weight, const data_t *g, data_t *dw,
const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int z = blockIdx.z;
if (x < width && y < height && z < height+width-1) {
for (int batch = 0; batch < num; ++batch) {
for (int plane = 0; plane < chn; ++plane) {
data_t _dout = dout[(batch * chn + plane) * sp + y*width + x];
if (z < width) {
int i = z;
data_t _g = g[(batch * chn + plane) * sp + y*width + i];
dw[(batch * len + i) * sp + y*width + x] += _dout * _g;
} else {
int i = z - width;
int j = i
data_t _g = g[(batch * chn + plane) * sp + j*width + x];
dw[(batch * len + width + i) * sp + y*width + x] += _dout * _g;
}
}
}
}
}
template
__global__ void initg(data_t *dg, const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int z = blockIdx.z;
if (x < width && y < height && z < chn) {
for (int batch = 0; batch < num; ++batch) {
//dweight[(batch * len + z%len) * sp + y*width + x] = (data_t)0.0;
dg[(batch * chn + z) * sp + y*width + x]=(data_t)0.0;
}
}
}
template
__global__ void initw(data_t * dweight, const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int z = blockIdx.z;
if (x < width && y < height && z < chn) {
for (int batch = 0; batch < num; ++batch) {
dweight[(batch * len + z) * sp + y*width + x] = (data_t)0.0;
//dg[(batch * chn + z) * sp + y*width + x]=(data_t)0.0;
}
}
}
template
__global__ void ca_map_backward_kernel_g(const data_t *dout, const data_t *weight, const data_t *g, data_t *dg,
const int num, const int chn, const int height, const int width) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int sp = height * width;
int len = height + width - 1;
int plane = blockIdx.z;
if (x < width && y < height && plane < chn) {
for (int batch = 0; batch < num; ++batch) {
for (int i = 0; i < width; ++i) {
data_t _dout = dout[(batch * chn + plane) * sp + y*width + i];
data_t _w = weight[(batch * len + x) * sp + y*width + i];
dg[(batch * chn + plane) * sp + y*width + x] += _dout * _w;
}
for (int i = 0; i < height; ++i) {
if (i == y) continue;
int j = i>y ? y : y-1;
data_t _dout = dout[(batch * chn + plane) * sp + i*width + x];
data_t _w = weight[(batch * len + width + j) * sp + i*width + x];
dg[(batch * chn + plane) * sp + y*width + x] += _dout * _w;
}
}
}
}
std::vector CA_MAP_Forward_GPU(
const paddle::Tensor& weight,const paddle::Tensor& g,
int N, int C, int H, int W) {
auto out = paddle::Tensor(paddle::PlaceType::kGPU,g.shape());
// NOLINT_NEXT_LINE(whitespace/operators)
dim3 threads(32, 32);
dim3 blocks((W+threads.x-1)/threads.x, (H+threads.y-1)/threads.y, C);
PD_DISPATCH_FLOATING_TYPES(
g.type(),"initout",([&]{
initout<<>>(
out.mutable_data(),N,C,H,W);
}));
PD_DISPATCH_FLOATING_TYPES(
g.type(),"ca_map_forward_kernel",([&]{
ca_map_forward_kernel<<>>(
weight.data(), g.data(), out.mutable_data(),N,C,H,W);
}));
return {out};
}
std::vector CA_MAP_Backward_GPU(const paddle::Tensor& weight,const paddle::Tensor& g,
const paddle::Tensor& out,const paddle::Tensor& dout,
int N, int C, int H, int W){
dim3 threads(32, 32);
int d1 = (W+threads.x-1)/threads.x;
int d2 = (H+threads.y-1)/threads.y;
int d3 = H+W;
dim3 hwblocks(d1, d2, d3);
dim3 cblocks(d1,d2,C);
auto dg = paddle::Tensor(paddle::PlaceType::kGPU,g.shape());
auto dw = paddle::Tensor(paddle::PlaceType::kGPU,weight.shape());
PD_DISPATCH_FLOATING_TYPES(
g.type(),"initg",([&]{
initg<<>>(
dg.mutable_data(),N,C,H,W);
}));
PD_DISPATCH_FLOATING_TYPES(
g.type(),"initw",([&]{
initw<<>>(
dw.mutable_data(),N,H+W-1,H,W);
}));
PD_DISPATCH_FLOATING_TYPES(
g.type(),"ca_map_backward_kernel_w",([&]{
ca_map_backward_kernel_w<<>>(
dout.data(), weight.data(), g.data(), dw.mutable_data(),N,C,H,W);
}));
PD_DISPATCH_FLOATING_TYPES(
g.type(),"ca_map_backward_kernel_g",([&]{
ca_map_backward_kernel_g<<>>(
dout.data(), weight.data(), g.data(),dg.mutable_data(),N,C,H,W);
}));
return {dw,dg};
}
.cc文件
#include "paddle/extension.h"
#include
std::vector CA_MAP_Forward_GPU(
const paddle::Tensor& weight,const paddle::Tensor& g,
int N, int C, int H, int W);
std::vector CA_MAP_Backward_GPU(
const paddle::Tensor& weight,const paddle::Tensor& g,
const paddle::Tensor& out,const paddle::Tensor& dout,
int N, int C, int H, int W);
std::vector CAMAPForward(
const paddle::Tensor& weight,const paddle::Tensor& g,
int N, int C, int H, int W) {
return CA_MAP_Forward_GPU(
weight,g,
N, C, H, W);
}
std::vector CAMAPBackward(
const paddle::Tensor& weight,const paddle::Tensor& g,
const paddle::Tensor& out,const paddle::Tensor& dout,
int N, int C, int H, int W) {
return CA_MAP_Backward_GPU(
weight,g,
out,dout,
N, C, H, W);
}
std::vector> CAMAPInferShape(std::vector weight_shape,std::vector g_shape) {
return {g_shape};
}
std::vector CAMAPInferDtype(paddle::DataType weight,paddle::DataType g){
return {g};
}
PD_BUILD_OP(camap)
.Inputs({"weight","g"})
.Outputs({"out"})
.Attrs({"N: int","C: int","H:int","W:int"})
.SetKernelFn(PD_KERNEL(CAMAPForward))
.SetInferShapeFn(PD_INFER_SHAPE(CAMAPInferShape))
.SetInferDtypeFn(PD_INFER_DTYPE(CAMAPInferDtype));
PD_BUILD_GRAD_OP(camap)
.Inputs({"weight", "g","out",paddle::Grad("out")})
.Outputs({paddle::Grad("weight"),paddle::Grad("g")})
.Attrs({"N: int","C: int","H:int","W:int"})
.SetKernelFn(PD_KERNEL(CAMAPBackward));


抱歉,是否可以详细描述一下问题,或者是附上一些截图?
我改了一下,能跑了,但是loss下降,验证结果一直为0
https://aistudio.baidu.com/aistudio/projectdetail/2535559?contributionType=1&shared=1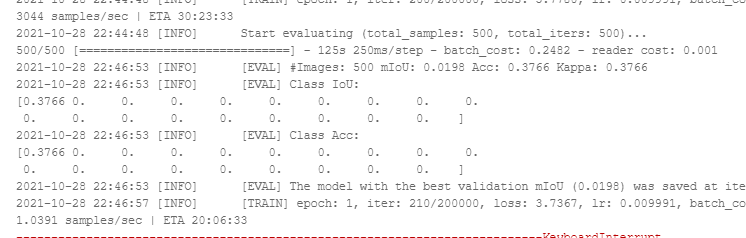
cuda 的代码是我搬过来的应该没啥大问题,不知道怎么回事?
解决了吗
这个图中Loss值由3点几,可以观察一下Loss继续下降之后,验证准确率是否还是为0。如果还是得话,估计是Loss计算错了。
不好意思,之前解决了,我把softmax 维度搞错,搞在最后一维了