
@[TOC](目录)
# 1 模型选择
## 1.1 回归任务
### 1.1.1 人脸关键点检测
完整代码详见[基于空间注意力SAM的GoogLeNet实现人脸关键点检测并自动添加表情贴纸](https://aistudio.baidu.com/aistudio/projectdetail/1533049)

68点的人脸关键点检测:
- 1-17:人脸的下轮廓
- 18-27:眉毛
- 28-36: 鼻子
- 37-48:眼睛
- 49-68:嘴巴点检测
## 1.2 分类任务
> CIFAR-10数据集也是分类任务中一个非常经典的数据集,在科研中,常常使用CIFAR数据集评估算法的性能。
### 1.2.1 图像分类
基于CIFAR-10数据集实现图像10分类。项目完整代码详见:[从论文到代码深入解析带有门控单元的gMLP算法](https://aistudio.baidu.com/aistudio/projectdetail/2134364)
gMLP中,最核心的部分就是**空间选通单元(Spatial Gating Unit,SGU)**,它的结构如下图所示:
## 1.3 场景任务
这里说的场景任务是针对某一个特定的场景开发的深度学习任务,相比于回归和分类任务来说,场景任务的难度更高。这里说的场景任务包括但不限于目标检测、图像分割、文本生成、语音合成、强化学习等。
- [PaddleX模型库](https://paddlex.readthedocs.io/zh_CN/develop/appendix/model_zoo.html)
- [PaddleGAN模型库](https://gitee.com/paddlepaddle/PaddleGAN/blob/master/docs/zh_CN/apis/apps.md)
- [PaddleOCR模型库](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/models_list.md)
- [PaddleHub模型库](https://www.paddlepaddle.org.cn/hublist)
# 2 模型训练
## 2.1 基于高层API训练模型
```
import paddle
# 使用paddle.Model完成模型的封装
model = paddle.Model(Net)
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 调用fit()接口来启动训练过程
model.fit(train_dataset,
epochs=1,
batch_size=64,
verbose=1)
```
## 2.2 使用PaddleX训练模型
### 2.2.1 YOLOv3模型的训练接口示例,函数内置了piecewise学习率衰减策略和momentum优化器。
```
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.000125,
lr_decay_epochs=[210, 240],
save_dir='output/yolov3_darknet53',
use_vdl=True)
```
### 2.2.2 配置数据集
```
from paddlex.det import transforms
import paddlex as pdx
# 下载和解压昆虫检测数据集
insect_dataset = 'https://bj.bcebos.com/paddlex/datasets/insect_det.tar.gz'
pdx.utils.download_and_decompress(insect_dataset, path='./')
# 定义训练和验证时的transforms
# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/det_transforms.html
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250), transforms.RandomDistort(),
transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize(
target_size=608, interp='RANDOM'), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.Resize(
target_size=608, interp='CUBIC'), transforms.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-vocdetection
train_dataset = pdx.datasets.VOCDetection(
data_dir='insect_det',
file_list='insect_det/train_list.txt',
label_list='insect_det/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='insect_det',
file_list='insect_det/val_list.txt',
label_list='insect_det/labels.txt',
transforms=eval_transforms)
```
### 2.2.3 初始化模型
```
# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.html
num_classes = len(train_dataset.labels)
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#paddlex-det-yolov3
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
```
### 2.2.4 模型训练
```
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#id1
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
learning_rate=0.000125,
lr_decay_epochs=[210, 240],
save_dir='output/yolov3_darknet53',
use_vdl=True)
```
## 2.3 模型训练通用配置基本原则
1. 每个输入数据的维度要保持一致,且一定要和模型输入保持一致。
2. 配置学习率衰减策略时,训练的上限轮数一定要计算正确。
3. BatchSize不宜过大,太大容易内存溢出,且一般为2次幂。
# 3 超参优化
## 3.1 超参优化基本概念
### 3.1.1 参数
参数是机器学习算法的关键,是从训练数据中学习到的,属于模型的一部分。

输入一个值(x),乘以权重,结果就是网络的输出值。权重可以随着网络的训练进行更新,从而找到最佳的值,这样网络就能尝试匹配输出值与目标值。
这里的权重其实就是一种参数。
### 3.1.2 超参数
模型的超参数指的是**模型外部**的配置变量,是不能通过训练的进行来估计其取值不同的,且不同的训练任务往往需要不同的超参数。
超参数不同,最终得到的模型也是不同的。
一般来说,超参数有:**学习率**,**迭代次数**,**网络的层数**,**每层神经元的个数**等等。
常见的超参数有以下三类:
1. **网络结构**,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数的类型等 .
2. **优化参数**,包括优化方法、学习率、小批量的样本数量等 .
3. **正则化系数**
实践中,当你使⽤神经⽹络解决问题时,**寻找好的超参数其实是一件非常困难的事情**,对于刚刚接触的同学来说,都是"佛系调优",这也是一开始就"入土"的原因,没有依据的盲目瞎调肯定是不行的。
## 3.2 手动调整参数的四大方法
### 1) Early stopping
### 2) 让学习率从高逐渐降低
### 3) 宽泛策略
### 4) 小批量数据(mini-batch)大小不必最优
# 4 效果演示
## 4.1 可视化 输入与输出
直接可视化输入与输出是最直接的方法。
```
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread(PATH_TO_IMAGE)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.show()
```
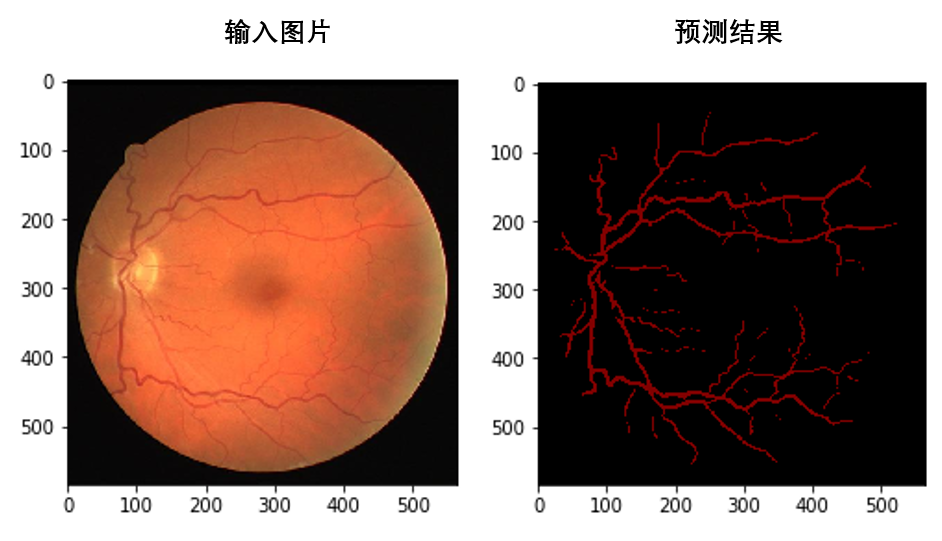
## 4.2 巧用VisualDL
VisualDL文档:[https://ai.baidu.com/ai-doc/AISTUDIO/Dk3e2vxg9#visualdl%E5%B7%A5%E5%85%B7](https://ai.baidu.com/ai-doc/AISTUDIO/Dk3e2vxg9#visualdl%E5%B7%A5%E5%85%B7)
完整示例代码请参考:[VisualDL2.2全新升级--可视化分析助力模型快速开发](https://aistudio.baidu.com/aistudio/projectdetail/1990920)
## 4.3 VisualDL可视化流程
1. 创建日志文件:
*为了快速找到最佳超参,训练9个不同组合的超参实验,创建方式均相同如下:
```
writer = LogWriter("./log/lenet/run1")
```
2. 训练前记录每组实验的超参数名称和数值,且记录想要展示的模型指标名称
```
writer.add_hparams({'learning rate':0.0001, 'batch size':64, 'optimizer':'Adam'}, ['train/loss', 'train/acc'])
```
**注意:这里记录的想要展示的模型指标为'train/loss'和 'train/acc',后续切记需要用`add_scalar`接口记录对应数值**
3. 训练过程中插入作图语句,记录accuracy和loss的变化趋势,同时将展示于Scalar和HyperParameters两个界面中:
```
writer.add_scalar(tag="train/loss", step=step, value=cost)
writer.add_scalar(tag="train/acc", step=step, value=accuracy)
```
4. 记录每一批次中的第一张图片:
```
img = np.reshape(batch[0][0], [28, 28, 1]) * 255
writer.add_image(tag="train/input", step=step, img=img)
```
5. 记录训练过程中每一层网络权重(weight)、偏差(bias)的变化趋势:
```
writer.add_histogram(tag='train/{}'.format(param), step=step, values=values)
```
6. 记录分类效果--precision & recall曲线:
```
writer.add_pr_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)
writer.add_roc_curve(tag='train/class_{}_pr_curve'.format(i),
labels=label_i,
predictions=prediction_i,
step=step,
num_thresholds=20)
```
7. 保存模型结构:
```
fluid.io.save_inference_model(dirname='./model', feeded_var_names=['img'],target_vars=[predictions], executor=exe)
```
## 4.4 权重可视化
> 在我们训练完网络之后,可以通过权重可视化,直观的理解网络到底学习到了什么
InterpretDL源码:[https://github.com/PaddlePaddle/InterpretDL](https://github.com/PaddlePaddle/InterpretDL)

# 5 总结
+ 对于模型组网,最重要的是学会使用SubClass形式组网,使用套件虽然简单,但是可定制化程度较低,如果是科研需要,建议一定要学会用SubClass形式组网
+ 模型训练是本文中最简单的部分,只需要按照文档在操作即可,但是超参数的选择有很多讲究,超参的好坏往往会影响模型的最终结果
+ 效果展示是一个项目的加分项,如果是科研需要,那么你也需要可视化地展示你的工作成果,这也是十分重要的

