
百度深度学习集训营已经正式开营,每个阶段的作业都将有各自的奖励,欢迎大家学习~
PS:如遇帖子过期、审核不通过的情况,请先复制内容保存在word文档,然后根据提示,完成个人实名验证,刷新后重新粘贴复制的内容,即可提交~
欢迎大家报名参加~
1月9日作业:
作业9-1:在第二章中学习过如何设置学习率衰减,这里建议使用分段衰减的方式,衰减系数为0.1, 根据ResNet目前的训练情况,应该在训练到多少步的时候设置衰减合适?请设置好学习率衰减方式,在眼疾识别数据集iChallenge-PM上重新训练ResNet模型。
作业9-1奖励:在作业中随机各抽取5名同学送出飞桨本+数据线+飞桨贴纸
回复帖子形式: 作业9-1:XXX
抽奖作业截止时间:2020年1月13日中午12点之前
作业9-2奖励:在作业中随机各抽取5名同学送出飞桨本+数据线+飞桨贴纸
回复帖子形式: 作业9-2:XXX
抽奖作业截止时间:2020年1月13日中午12点之前
1月7日作业:
作业8:如果将LeNet模型中的中间层的激活函数Sigmoid换成ReLU,在眼底筛查数据集上将会得到什么样的结果?Loss是否能收敛,ReLU和Sigmoid之间的区别是引起结果不同的原因吗?请发表你的观点
作业8奖励:在作业中随机各抽取5名同学送出飞桨本+数据线+飞桨贴纸
回复帖子形式: 作业8:XXX
获奖同学:#820 thunder95、#819 你还说不想我吗、 #818 百度用户#0762194095、#817 呵赫 he、#816 星光1dl
1月2日作业
作业7-1 计算卷积中一共有多少次乘法和加法操作
输入数据形状是[10, 3, 224, 224],卷积核kh = kw = 3,输出通道数为64,步幅stride=1,填充ph = pw =1
完成这样一个卷积,一共需要做多少次乘法和加法操作?
提示:先看输出一个像素点需要做多少次乘法和加法操作,然后再计算总共需要的操作次数
提交方式:请回复乘法和加法操作的次数,例如:乘法1000,加法1000
作业7-1奖励:抽取5人赢得飞桨定制本+数据线,截止时间2020年1月6日中午12点之前
回复帖子形式: 作业7-1:XXX
作业7-2奖励:从正确答案中抽取5人获得飞桨定制本+50元京东卡,截止时间2020年1月6日中午12点之前
12月31日作业
作业6-1:
1.将普通神经网络模型的每层输出打印,观察内容
2.将分类准确率的指标 用PLT库画图表示
3.通过分类准确率,判断以采用不同损失函数训练模型的效果优劣
4.作图比较:随着训练进行,模型在训练集和测试集上的Loss曲线
5.调节正则化权重,观察4的作图曲线的变化,并分析原因
作业6-1奖励:抽取5人赢得飞桨定制本+数据线 ,回复帖子形式: 作业6-1:XXX
作业6-2:
正确运行AI Studio《百度架构师手把手教深度学习》课程里面的作业3 的极简版代码,分析训练过程中可能出现的问题或值得优化的地方,通过以下几点优化:
(1)样本:数据增强的方法
(2)假设:改进网络模型
(2)损失:尝试各种Loss
(2)优化:尝试各种优化器和学习率
目标:尽可能使模型在mnist测试集上的分类准确率最高
提交实现最高分类准确率的代码和模型,我们筛选最优结果前10名进行评奖
作业6-2奖励:飞桨定制本+50元京东卡
12月25日作业
12月23日作业
作业4-1:在AI studio上运行作业2,用深度学习完成房价预测模型
作业4-1奖励:飞桨定制本+ 《深度学习导论与应用实践》教材,选取第2、3、23、123、223、323…名同学送出奖品
作业4-2:回复下面问题,将答案回复帖子下方:
通过Python、深度学习框架,不同方法写房价预测,Python编写的模型 和 基于飞桨编写的模型在哪些方面存在异同?例如程序结构,编写难易度,模型的预测效果,训练的耗时等等?
回复帖子形式: 作业4-2:XXX
作业4-2奖励:在12月27日(本周五)中午12点前提交的作业中,我们选出最优前五名,送出百度定制数据线+《深度学习导论与应用实践》教材
12月17日作业
完成下面两个问题,并将答案回复在帖子下面,回帖形式:作业3-1(1)XX(2)XX
作业奖励:在2019年12月20日中午12点之前提交,随机抽取5名同学进行点评,礼品是本+数据线
12月12日作业
获奖者:第12名:飞天雄者
12月10日作业
作业1-1:在AI Studio平台上https://aistudio.baidu.com/aistudio/education/group/info/888 跑通房价预测案例
作业1-1奖励:最先完成作业的前3名,以及第6名、66名、166名、266名、366名、466名、566名、666名的同学均可获得飞桨定制大礼包:飞桨帽子、飞桨数据线 、飞桨定制logo笔
作业1-1的获奖者如图:
作业1-2:完成下面两个问题,并将答案发布在帖子下面
①类比牛顿第二定律的案例,在你的工作和生活中还有哪些问题可以用监督学习的框架来解决?假设和参数是什么?优化目标是什么?
②为什么说AI工程师有发展前景?怎样从经济学(市场供需)的角度做出解读?
作业1-2奖励:回复帖子且点赞top5,获得《深度学习导论与应用实践》教材+飞桨定制本
点赞Top5获奖者:1.飞天雄者 2.God_s_apple 3.177*******62 4.学痞龙 5.故乡237、qq526557820
作业截止时间2020年1月10日,再此之前完成,才有资格参加最终Mac大奖评选
报名流程:
1.加入QQ群:726887660,班主任会在QQ群里进行学习资料、答疑、奖品等活动
2.点此链接,加入课程报名并实践:https://aistudio.baidu.com/aistudio/course/introduce/888
温馨提示:课程的录播会在3个工作日内上传到AI studio《百度架构师手把手教深度学习》课程上


作业5-1:
随机选取100张图片的预测结果:
个人作业是在 2-5【手写数字识别】之损失函数 的代码的基础上做修改完成的,主要重写了load_image函数,以及最后测试的时候的代码
作业5-2:
LeNet:由深度学习三巨头之一的Yan LeCun提出,LeNet的实现确立了CNN的结构
AlexNet:AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。
(3)在CNN中使用重叠的最大池化。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
(6)数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。
VGGNet:主要特点在于:(1)网络很深;(2)卷积层中使用的卷积核很小,且都是3*3的卷积核。
Inception:主要思路是:如何使用一个密集成分来近似或者代替最优的局部稀疏结构
ResNet:解决“随着网络加深,准确率不下降”的问题
DenseNet:主要特点:
(1)减轻了vanishing-gradient(梯度消失)
(2)加强了feature的传递
(3)更有效地利用了feature
(4)一定程度上较少了参数数量
MobileNet:最大的特点就是采用depth-wise separable convolution来减少运算量以及参数量
ShuffleNet:核心就是用pointwise group convolution,channel shuffle和depthwise separable convolution代替ResNet block的相应层构成了ShuffleNet uint,达到了减少计算量和提高准确率的目的。channel shuffle解决了多个group convolution叠加出现的边界效应,pointwise group convolution和depthwise separable convolution主要减少了计算量。
作业5-3:
(1)比较采用SGD优化方法的情况下learning_rate为多少时相对更佳
根据二分法的方式,之后的调整learning_rate的区间应该为 >0.01的部分,可以先看一下 learning_rate>0.1时的情况,再二分调整区间。
(2)比较learning_rate = 0.01 时哪一种优化算法的效果更好
拿来做比较的算法有:SGD,Momentum,Adagrad,Adam
(这部分代码直接采用的是 2-6【手写数字识别】之优化算法 的代码,其中使用Momentum优化器的那一行代码少了参数momentum,之后自己赋经验值momentum=0.9传入函数)
另外其他的优化函数还有
1、NAG:在Momentum的基础上引入下一个位置的梯度
2、Adadelta:对Adagrad的改进,缓解浓密产率的快速下降
3、RMSprop:使梯度积累项按一定比例衰减,解决了Adagrad中学习率急剧下降的问题
4、AdaMax:对Adam的改进,使用梯度无穷矩来构造学习率自适应因子,动量依然为矩阵的一阶矩
5、Nadm:在Adam的基础上结合了NAG,Nadam修改了梯度的一阶矩,梯度的二阶矩不变
比较之下看来,对于MNIST手写字体识别这个问题来说,优化方法的好坏顺序为:Adam>Momentum>SGD>Adagrad
作业:
5-1:
测试分类模型
with fluid.dygraph.guard():
model = MNIST("mnist")
params_file_path = 'mnist3'
# 加载模型参数
model_dict, _ = fluid.load_dygraph(params_file_path)
model.load_dict(model_dict)
model.eval() # 这个?
allnum = 0
accnumm = 0
for i in index_list[0:100]:
# 读取图像和标签,转换其尺寸和类型
img = np.reshape(imgs[i], [1, 28, 28]).astype('float32')
label1 = np.reshape(labels[i], [1]).astype('int64')
imge = np.array([img])
la = np.array([label1])
image = fluid.dygraph.to_variable(imge)
label = fluid.dygraph.to_variable(la)
result = model(image)
allnum += 1
resn =result.numpy()
reslable =np.argmax(resn)
if reslable == label1[0]:
accnumm +=1
print("本次预测的数字是", np.argmax(result.numpy()),'答案是',label1,'对的',resn[0][reslable])
else:
print("本次预测的数字是", np.argmax(result.numpy()),'答案是',label1,'-------预测错误',resn[0][reslable])
print('一共{}割数据, 准确率:{}'.format(allnum,accnumm/allnum))
>>>
本次预测的数字是 9 答案是 [8] -------预测错误 0.97425735
本次预测的数字是 9 答案是 [9] 对的 0.998828
本次预测的数字是 1 答案是 [1] 对的 0.9983575
本次预测的数字是 4 答案是 [4] 对的 1.0
本次预测的数字是 3 答案是 [3] 对的 0.88509685
本次预测的数字是 7 答案是 [7] 对的 0.9999999
本次预测的数字是 6 答案是 [6] 对的 0.99999857
本次预测的数字是 1 答案是 [1] 对的 0.99999595
本次预测的数字是 6 答案是 [8] -------预测错误 0.5963251
本次预测的数字是 4 答案是 [4] 对的 0.99999726
本次预测的数字是 9 答案是 [9] 对的 0.9999933
本次预测的数字是 7 答案是 [7] 对的 0.99993837
本次预测的数字是 6 答案是 [6] 对的 1.0
本次预测的数字是 1 答案是 [1] 对的 0.9996762
一共100割数据, 准确率:0.96
5-2:
常见的卷积神经网络
LeNet
AlexNet
VGG
Inception Net
ResNet
DenseNet
MobileNet
ShuffleNet
参考链接
https://zhuanlan.zhihu.com/p/76275427
https://blog.csdn.net/u012679707/article/details/80870625
卷积层 + 池化层(Pooling Layer) + 全连接层
Dropout?
减小 L2 正则化项?
Weight decay?
“感受野”?
Top-1/Top-5?
卷积核大小为 1 × 1,3 × 3,5 × 5
grid search?
5-3:
手写数字识别任务
在不同学习率下每种优化器的表现都不一样 在各自对当前模型比较合适的学习率的情况下都能达到很好的效果,在训练集准确率0.99以上,在测试集0.98以上
loss最终都比较小值的平滑下来,训练次数越多测试集准确率会降低 训练集准确率会升高
RMSPropOptimizer 学习率在0.001 在训练集和测试集的准确率都大于98%
学习率
[0.9, 0.75, 0.5, 0.25, 0.1, 0.075, 0.05, 0.025, 0.01, 0.0075, 0.005, 0.0025, 0.001, 0.0001]
不设置 regularization
批次大小 100
EPOCH_NUM 10
net定义
class MNIST(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(MNIST, self).__init__(name_scope)
name_scope = self.full_name()
self.conv1 = Conv2D(name_scope, num_filters=20, filter_size=5, stride=1, padding=2)
self.pool1 = Pool2D(name_scope, pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(name_scope, num_filters=20, filter_size=5, stride=1, padding=2)
self.pool2 = Pool2D(name_scope, pool_size=2, pool_stride=2, pool_type='max')
self.fc = FC(name_scope, size=10, act='softmax')
def forward(self, inputs, label=None, check_shape=False, check_content=False):
# 给不同层的输出不同命名,方便调试
outputs1 = self.conv1(inputs)
outputs2 = self.pool1(outputs1)
outputs3 = self.conv2(outputs2)
outputs4 = self.pool2(outputs3)
outputs5 = self.fc(outputs4)
# 如果label不是None,则计算分类精度并返回
if label is not None:
acc = fluid.layers.accuracy(input=outputs5, label=label)
return outputs5, acc
else:
return outputs5
A.
1.SGD
学习率在0.0025-0.075 范围都比较好
2.Moment
在momentum=0.9,
各个学习率下的 评估集准确率曲线,训练集准确率曲线,训练loss
Moment优化器中比较好的
学习率在0.0025-0.025之间的都比较好 测试集训练集准确率在0.98-0.99
momentum = [1.0, 0.95, 0.9, 0.85, 0.7, 0.5, 0.1] 学习率 = 0.001
曲线如下
在momentum =1.0 时影响比较大 在0.95时在此处最优
3.Adag
学习率在0.001-0.0025 比较好
4.RMSP
学习率在0.001-0.0025 比较好
5.Adam
学习率在0.0001-0.01范围比较好
6.Adamax
学习率在0.001-0.025范围还可以
7.Decay
学习率在0.001-0.005范围还可以
8.FtrlO
学习率在0.0025-0.1范围还可以
B.
加入
regularization
[1.0, 0.5, 0.1, 0.05, 0.005, 0.0005, 0.00005]
对RMSPropOptimizer
测试
regularization的值越大 对训练是的准确率和loss影响越大 抑制训练时参数的变化?
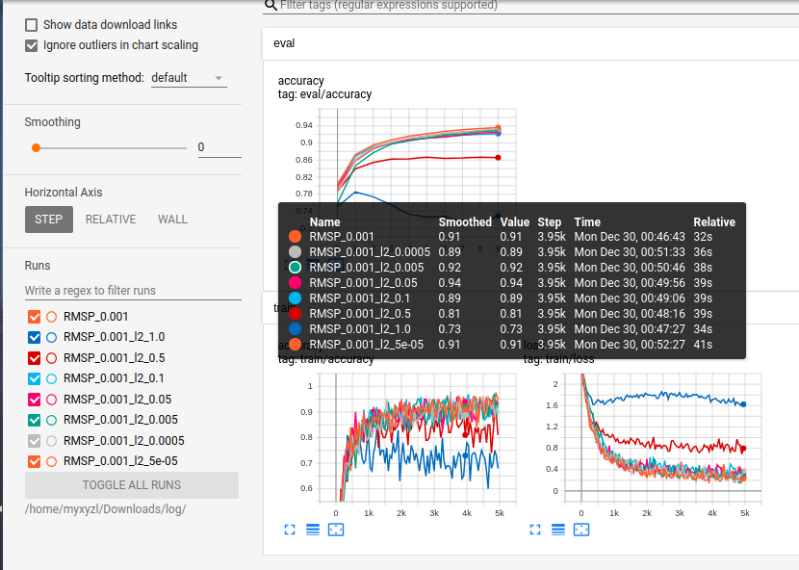
作业5:
作业5-1
得到对随机100张图片数据的预测精度0.91
作业4-2:对预测任务的执行过程整体流程相同的,需要先处理数据,设置模型结构,训练模型,保存模型,导入模型,在测试集进行验证
不同在于,适应飞桨框架后再搭建模型结构的时候,极大的有了简化,很多以前需要手动实现的函数,功能都直接有了可以调用的接口或者方法,极大的提供高了编程效率,验证速度等优势,而且可读性也高,预测效果更方便,通过支持的gpu模式,以及多卡多机等方式使得训练更快捷,很强大
5-2:
常见的卷积网络:
1.LeNet-5:最早在编码数字分类有好的效果,一个五层网络结果;
2.AlexNet,2012年ImageNet提出,结构事使用5层卷积+3个fc层,softmax实现1000分类;首次使用数据增广;用ReLU代替Sigmoid增加收敛速度;使用多GPU计算;加入Dropout等;
3.VGGNet,来自论文《Very Deep Convolutional Networks for Large-Scale Visual Recognition》,是一个深层网络结构,现在实际应用中主要在工程实践中用到的,常见的是16层,而且使用了Pre-training的方式,加入BatchNormalization。
4.GoogLeNet:2014提出的新网络结构,Inception结构代替了单纯的卷积+激活的传统操作,引入Inception结构,一个Block通过1x1卷积 池化 3x3 卷积 5x5卷积,最后在通道维上连结,实现较好的准确率
5.ResNet,残差网络结构,还没太了解这个,实现恒等映射,防止过深的网络导致梯度消失,这样的结构延续至今,可以结合目前流行的网络使用。
6.DenseNet,CVPR 2017最佳论文,(Dense Convolutional Network),网络结构很深,通过采用密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
7.Mixnet, 通过多个卷积核卷积连结,减小参数量的同时提高精度
8.ResNeXt:2017ILSVRC增加了子模块的拓扑结构;cardinality(基数);网络研究中提高增加 cardinality 比增加深度和宽度更有效;可以实现在不增加参数复杂度的前提下提高准确率,减少了超参数的数量;
作业5-3:
通过几组简单的test实验
Adam>Momentum>SGD>Adagrad
其中adam在学习率为0.001,观察loss的变化较好,这个只是实验,实际应用中的话,对于大数据量,要通过这种一一去试的方法不太可行,一般都是按照经验用0.01了,对不同问题也许sgd的效果就已经可以达到想要的效果了
作业5-1:[1.png]、[2.png]、[3.png]
作业5-2:ShuffleNet、GoogleNet、LeNet、MobileNet、Alexnet、VGG、ResNext
作业5-3:在学习率0.002时,Adam最好。
作业5-1,随机抽取100张图片,测试模型准确率;
三个模型分别是一层网络,全连接网络,卷积神经网络。
# 定义mnist数据识别网络结构,同房价预测网络 class MNIST3(fluid.dygraph.Layer): def __init__(self, name_scope): super(MNIST3, self).__init__(name_scope) name_scope = self.full_name() # 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数 self.fc = FC(name_scope, size=1, act=None) # 定义网络结构的前向计算过程 def forward(self, inputs): outputs = self.fc(inputs) return outputs # 多层全连接神经网络实现 class MNIST1(fluid.dygraph.Layer): def __init__(self, name_scope): super(MNIST1, self).__init__(name_scope) name_scope = self.full_name() # 定义两层全连接隐含层,输出维度是10,激活函数为sigmoid self.fc1 = FC(name_scope, size=10, act='sigmoid') # 隐含层节点为10,可根据任务调整 self.fc2 = FC(name_scope, size=10, act='sigmoid') # 定义一层全连接输出层,输出维度是1,不使用激活函数 self.fc3 = FC(name_scope, size=1, act=None) # 定义网络的前向计算 def forward(self, inputs, label=None): outputs1 = self.fc1(inputs) outputs2 = self.fc2(outputs1) outputs_final = self.fc3(outputs2) if label is not None: acc = fluid.layers.accuracy(input=outputs_final, label=label) return outputs_final, acc else: return outputs_final # 多层卷积神经网络实现 class MNIST2(fluid.dygraph.Layer): def __init__(self, name_scope): super(MNIST2, self).__init__(name_scope) name_scope = self.full_name() # 定义卷积层,输出特征通道num_filters设置为20,卷积核的大小filter_size为5,卷积步长stride=1,padding=2 # 激活函数使用relu self.conv1 = Conv2D(name_scope, num_filters=20, filter_size=5, stride=1, padding=2, act='relu') # 定义池化层,池化核pool_size=2,池化步长为2,选择最大池化方式 self.pool1 = Pool2D(name_scope, pool_size=2, pool_stride=2, pool_type='max') # 定义卷积层,输出特征通道num_filters设置为20,卷积核的大小filter_size为5,卷积步长stride=1,padding=2 self.conv2 = Conv2D(name_scope, num_filters=20, filter_size=5, stride=1, padding=2, act='relu') # 定义池化层,池化核pool_size=2,池化步长为2,选择最大池化方式 self.pool2 = Pool2D(name_scope, pool_size=2, pool_stride=2, pool_type='max') # 定义一层全连接层,输出维度是1,不使用激活函数 self.fc = FC(name_scope, size=1, act=None) # 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出 def forward(self, inputs): x = self.conv1(inputs) x = self.pool1(x) x = self.conv2(x) x = self.pool2(x) x = self.fc(x) return xepoch = 10, SGDOptimizer,lr=0.01
使用
来计算准确率,注意对与这个接口来说,输入参数必须是Tensor|LoDTensor,而且对数据类型有要求,input -数据类型为float32,float64,为预测值;label -数据类型为int64,int32。输入为数据集的标签,需要单独转换格式,代码中load_data的返回label为float32。
结论:卷积网络结构识别最好,由于训练次数有限,总体准确率不高,但从网络结构效果比较来说,已经可以得出结论。
作业5-2,对于计算机网络,常见的卷积神经网络有:
作业5-3 在手写数字识别任务上,哪种优化算法的效果最好,多大的学习率最优,通过Loss的下降趋势来判断?
(1)优化算法比较,MomentumOptimizer最好,优化算法主要优化的方向是参数更新的方向和大小。
实验设置:学习率 0.01
学习率调整比较,从损失下降稳定性和速度来说,lr=0.05效果最好。
实验设置:MomentumOptimizer,lr=0.1,0.05,0.01,0.005,0.001
作业5-2:
计算机视觉算法pro
作业5-1:
以2-8中的程序为例,batch=100,,准确率最高为0.99,,最低为0.94,总体准确率为0.97。
作业5-2:
常见的卷积神经网络:LeNet/AlexNet/ResNet/googleNet等,
作业5-2:
CNN
LSTM
作业:5-3
Adam最好。
学习率0.001
5-2:
常见的卷积网络:
1.LeNet-5:最早在编码数字分类有好的效果,一个五层网络结果;
2.AlexNet,2012年ImageNet提出,结构事使用5层卷积+3个fc层,softmax实现1000分类;首次使用数据增广;用ReLU代替Sigmoid增加收敛速度;使用多GPU计算;加入Dropout等;
3.VGGNet,来自论文《Very Deep Convolutional Networks for Large-Scale Visual Recognition》,是一个深层网络结构,现在实际应用中主要在工程实践中用到的,常见的是16层,而且使用了Pre-training的方式,加入BatchNormalization。
4.GoogLeNet:2014提出的新网络结构,Inception结构代替了单纯的卷积+激活的传统操作,引入Inception结构,一个Block通过1x1卷积 池化 3x3 卷积 5x5卷积,最后在通道维上连结,实现较好的准确率
5.ResNet,残差网络结构,还没太了解这个,实现恒等映射,防止过深的网络导致梯度消失,这样的结构延续至今,可以结合目前流行的网络使用。
6.DenseNet,CVPR 2017最佳论文,(Dense Convolutional Network),网络结构很深,通过采用密集连接:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
7.Mixnet, 通过多个卷积核卷积连结,减小参数量的同时提高精度
8.ResNeXt:2017ILSVRC增加了子模块的拓扑结构;cardinality(基数);网络研究中提高增加 cardinality 比增加深度和宽度更有效;可以实现在不增加参数复杂度的前提下提高准确率,减少了超参数的数量;
作业5-3:
优化算法比较(本机跑的代码)
Adam>Adagrad>Momentum>SGD
实际上Momentum和SGD表现几乎相同就以上排序就本机平均值而言的
生硬Adam优化器依次调整学习率为0.00001,0.0001,0.001,0.01
优化器Adam学习率在0.001时最优
作业 3-1
1.tanh 函数
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.patches as patches
plt.figure(figsize=(8,3))
x= np.arange(-10,10,0.1)
y = (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
plt.plot(x,y,color = 'pink')
plt.text(-5.,0.9,r'$y = tanh(x)$',fontsize = 13)
currentAxis = plt.gca()
currentAxis.xaxis.set_label_text('x',fontsize = 15)
currentAxis.yaxis.set_label_text('y',fontsize = 15)
plt.show()
2. 大于 0 元素统计
import numpy as np
p = np.random.randn(10,10)
q = (p>0)
q.sum()
12月17日
3-1:
#tahn函数
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.patches as patches
#设置图片大小
plt.figure(figsize=(8, 3))
# x是1维数组,数组大小是从-10. 到10.的实数,每隔0.1取一个点
x = np.arange(-10, 10, 0.1)
# 计算 tahn函数
t = (np.exp(x)-np.exp(- x)) / (np.exp(x) + np.exp(- x))
# 设置两个子图窗口,将Sigmoid的函数图像画在左边
f = plt.subplot(111)
# 画出函数曲线
plt.plot(x, t, color='b')
# 添加文字说明
plt.text(-7.5, 0.7, r'$y=tahn(x)$', fontsize=13)
# 设置坐标轴格式
currentAxis=plt.gca()
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)
3-2:
p = np.random.randn(10, 10)
q = (p>0)
print('q: {}, dtype: {}'.format(q,q.dtype))
sum=0
for i in range(10):
for j in range(10):
if q[i][j]==True:
sum +=1
print("The number of elements greater than 0 is:",sum)
import os
# 获取文件名
# 读取一张本地的样例图片,转变成模型输入的格式
def load_image(img_path):
# 从img_path中读取图像,并转为灰度图
im = Image.open(img_path).convert('L')
print(np.array(im))
im = im.resize((28, 28), Image.ANTIALIAS)
im = np.array(im).reshape(1, -1).astype(np.float32)
# 图像归一化,保持和数据集的数据范围一致
im = 2 - im / 127.5
return im
ri=0
fa=0
# 定义预测过程
with fluid.dygraph.guard():
model = MNIST("mnist")
params_file_path = 'mnist'
# 加载模型参数
model_dict, _ = fluid.load_dygraph("mnist")
model.load_dict(model_dict)
model.eval()
file_names = os.listdir("./work/")
#print(file_names)
for f in file_names:
if f.find("_")>0:
img_path = "./work/"+f
lab=int(float(f[f.find('_')+1:f.find('.png')]))
#print(lab)
tensor_img = load_image(img_path )
result = model(fluid.dygraph.to_variable(tensor_img))
if lab==result.numpy().astype('int32'):
ri+=1
else:
fa+=1
print(ri/100)
作业2-2挑战题:
建立一个神经网络模型,结构如下:
这是一个二层神经网络,输入层13个节点,有一个隐藏层,13个节点,输出层1个节点。简单起见,这里的层都不加激活函数,这是一个纯线性模型。
class Network(object): def __init__(self, weights_size): ''' weights_size: 包含各层节点数的list, 包含输入层 ''' # 随机产生w的初始值 # 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子 #np.random.seed(0) self.w = {} self.b = {} self.z = {} self.grad_w = {} self.grad_b = {} self.n_lays = len(weights_size) - 1 for l, size in enumerate(weights_size): if l == 0: continue self.w[l] = np.random.randn(size, weights_size[l-1]) self.b[l] = np.random.randn(size, 1) def forward(self, x): z = x for l in self.w: self.z[l] = np.dot(self.w[l], z) + self.b[l] z = self.z[l] return z def loss(self, z, y): error = z - y num_samples = error.shape[1] cost = error * error cost = np.sum(cost) / (2*num_samples) return cost def backward(self, x, z, y): n_samples = z.shape[1] delta = (1/n_samples)*(z-y) self.grad_w[self.n_lays] = np.dot(delta, self.z[self.n_lays-1].T) self.grad_b[self.n_lays] = np.sum(delta, axis=1, keepdims=True) for l in range(self.n_lays-1, 0, -1): delta = np.dot(self.w[l+1].T, delta) self.grad_w[l] = np.dot(delta, self.z.get(l, x).T) self.grad_b[l] = np.sum(delta, axis=1, keepdims=True) def forward_for_grad_check(self, x, w, b): z = x for l in w: z = np.dot(w[l], z) + b[l] return z def grad_check(self, x): epslon = 1e-7 w_plus = self.w w_minus = self.w b_plus = self.b b_minus = self.b s = 0 e = 0 for l, w in self.w.items(): for i in range(w.shape[0]): for j in range(w.shape[1]): # 改变一个元素,获取近似梯度 w_plus[l][i][j] = w[i][j] + epslon w_minus[l][i][j] = w[i][j] - epslon j_plus = self.loss(self.forward_for_grad_check(x, w_plus, self.b), y) j_minus = self.loss(self.forward_for_grad_check(x, w_minus, self.b), y) grad_approx = self.grad_w[l] grad_approx[i][j] = (j_plus - j_minus) / (2*epslon) # 近似梯度 # 比较通过反向传播获取的梯度是否和近似梯度相差过大 diff = np.linalg.norm(self.grad_w[l] - grad_approx) / \ (np.linalg.norm(self.grad_w[l]) + np.linalg.norm(grad_approx)) if diff < epslon: # print('grad correct') pass else: e += 1 # print('grad error') s += 1 # for l, b in self.b.items(): # for i in range(b.shape[0]): # for j in range(b.shape[1]): # # 改变一个元素,获取近似梯度 # b_plus[l][i][j] = b[i][j] + epslon # b_minus[l][i][j] = b[i][j] - epslon # j_plus = self.loss(self.forward_for_grad_check(x, self.w, b_plus), y) # j_minus = self.loss(self.forward_for_grad_check(x, self.w, b_minus), y) # grad_approx = self.grad_b[l] # grad_approx[i][j] = (j_plus - j_minus) / (2*epslon) # 近似梯度 # # 比较通过反向传播获取的梯度是否和近似梯度相差过大 # diff = np.linalg.norm(self.grad_b[l] - grad_approx) / \ # (np.linalg.norm(self.grad_b[l]) + np.linalg.norm(grad_approx)) # if diff < epslon: # # print('grad correct') # pass # else: # e += 1 # print('grad error') # s += 1 # print(e, s) def update(self, eta = 0.01): for l in range(1, self.n_lays+1): self.w[l] = self.w[l] - eta * self.grad_w[l] self.b[l] = self.b[l] - eta * self.grad_b[l] def train(self, training_data, num_epoches, batch_size=10, eta=0.01): n = training_data.shape[0] losses = [] for epoch_id in range(num_epoches): # 在每轮迭代开始之前,将训练数据的顺序随机的打乱, # 然后再按每次取batch_size条数据的方式取出 np.random.shuffle(training_data) # 将训练数据进行拆分,每个mini_batch包含batch_size条的数据 mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)] for iter_id, mini_batch in enumerate(mini_batches): #print(self.w.shape) #print(self.b) x = mini_batch[:, :-1].T y = mini_batch[:, -1:].T z = self.forward(x) loss = self.loss(z, y) self.backward(x, z, y) self.grad_check(x) # 执行梯度检查 self.update(eta) losses.append(loss) # print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'. # format(epoch_id, iter_id, loss)) return losses net = Network([13, 13 ,1]) losses = net.train(training_data, num_epoches=50, batch_size=404, eta=0.01) # 画出损失函数的变化趋势 plot_x = np.arange(len(losses)) plot_y = np.array(losses) plt.plot(plot_x, plot_y) plt.show()作业1-2:
①类比牛顿第二定律的案例,在你的工作和生活中还有哪些问题可以用监督学习的框架来解决?假设和参数是什么?优化目标是什么?
比如判断某个用户的金融信贷违约风险,可以用监督学习来处理。假设我们使用逻辑回归模型,假设就是用户特征的线性组合和违约风险具有线性相关性,这时候,参数是模型中的权重,优化目标是使模型在训练集上的交叉熵代价函数最小。
②为什么说AI工程师有发展前景?怎样从经济学(市场供需)的角度做出解读?
当前ai已经应用的生活的各个方面,产业化愈发成熟,而ai人才还比较少,造成来供小于求的局面,未来ai工程师的发展前景广阔。
作业4-2:
通过Python、深度学习框架,不同方法写房价预测,Python编写的模型 和 基于飞桨编写的模型在程序结构方面是相同的,但是在难易程度不同,用python实现需要自行关注底层细节,做重复工作,任务繁重,用飞桨就简单多了。训练的耗时方面,飞桨必定做了优化,必然比python干写块,比较python 本来就慢。