
引导篇:刚进入对抗攻击领域的童鞋,建议收藏。
相关论文:
2013:Intriguing properties of neural networks(开山之作)
2014:Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images
2017:Universal adversarial perturbations
最新进展↓(一头雾水的建议先看下面这个Survey)
2018(总结篇):Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
2018(总结篇):CAAD 2018: Generating Transferable Adversarial Examples
PPT:https://docs.google.com/presentation/d/1A73itjoA-j44UOuWvlwTqw6QWMIh6L_bA9WKGrtBsXQ/edit?usp=sharing
Adversarial Examples(对抗样本)
对抗样本(adversarial examples)和对抗学习(GAN)截然不同,这一概念在Szegedy et al. (2014b)中提出:对输入样本故意添加一些人无法察觉的细微的干扰,导致模型以高置信度给出一个错误的输出。
1.可以针对一张已经有正确分类的image,对其进行细微的像素修改,可以在DNN下被错分为其他label。

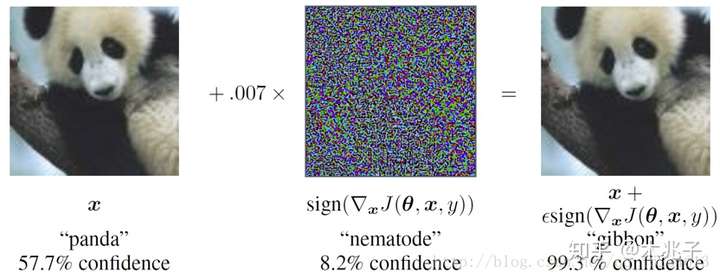
 样本x的label为熊猫,在对x添加部分干扰后,在人眼中仍然分为熊猫,但对深度模型,却将其错分为长臂猿,且给出了高达99.3%的置信度。
样本x的label为熊猫,在对x添加部分干扰后,在人眼中仍然分为熊猫,但对深度模型,却将其错分为长臂猿,且给出了高达99.3%的置信度。
 一像素攻击:改动图片上的一个像素,就能让神经网络认错图,甚至还可以诱导它返回特定的结果。
一像素攻击:改动图片上的一个像素,就能让神经网络认错图,甚至还可以诱导它返回特定的结果。改动图片上的一个像素,就能让神经网络认错图,甚至还可以诱导它返回特定的结果
2.同样,根据DNN,很容易产生一张在人眼下毫无意义的image,但是在DNN中能够获得高confidence的label。

 两种EA算法生成的样本,这些样本人类完全无法识别,但深度学习模型会以高置信度对它们进行分类,例如将噪声识别为狮子。
两种EA算法生成的样本,这些样本人类完全无法识别,但深度学习模型会以高置信度对它们进行分类,例如将噪声识别为狮子。So 怎么理解对抗样本?Anh Nguyen的论文《Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images》中有个比较形象的示意:
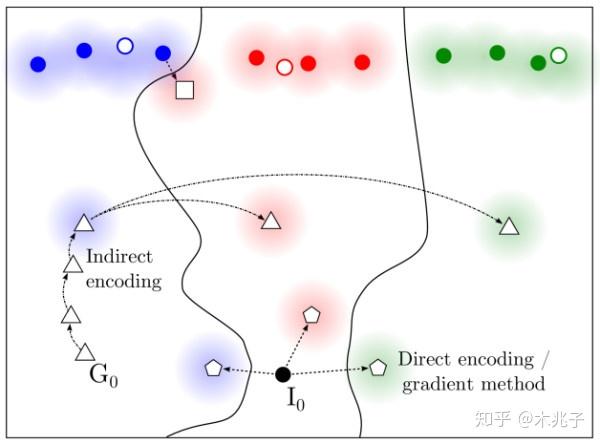
要理解这个图,还要提一句机器学习的一个基本问题:学习数据的分布。具体到方法就是从训练数据中进行学习,如果学习成功,则可以泛化到所有数据,包含没见过的测试数据。回到这个图,数据的分布就是最上边那三坨。一种造对抗样本的方法就是从一个类别的样本出发,做一些小修改,让模型将修改后的样本判断为另一个类别,而实际上(或是人的,显然的判断)该样本仍为原来类别,这就是图中从蓝色原点到白色小方块的方法。
当然更容易的方法是利用分类边界的不可确定性。比如上图中除了最上面部分的空间可以认为是数据存在概率极低的区域,从实际应用的角度甚至可以认为是我们完全不关心的区域。因为算法学习的样本只有实心的小圆点,所以远离小圆点的部分,分类边界是难以控制的。在这里面很容易轻松取到算法高概率认为是一个类别的样本,而实际上却难以辨认的对抗性样本。
所以大体来说,对抗性样本的存在是因为数据维度通常过高,即使考虑所在的子区域,往往还是过高,对整个(数据分布的)空间的搜索是不可行的。在训练样本没有覆盖的区域,无论该区域是否属于数据分布所在的区域,无论模型的capacity够不够,都有出现对抗性样本的可能。尽管深度学习中一直主张distributed representation已大幅优于局部泛化,维度的诅咒仍是一个无法摆脱的难题。
定量解释:

很多人认为是模型的高度非线性导致的该问题。但《EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES》解释恰恰由于其线性本身导致的。
以y = W^T * X举例(W是权重,X是输入)。如果X’ = X + t,t为干扰,W^T * X’ = W^T * X + W^T * t,也就是多出一个 W^T * t项,W和t维数很大时,即使很小扰动,累加起来也很可观。

 以上图二类器举例:只需一个小小改变,分类器就从5%的置信度上升到88%的置信度。
以上图二类器举例:只需一个小小改变,分类器就从5%的置信度上升到88%的置信度。AI Attack
攻击分类
White-box attack:白盒攻击,对模型和训练集完全了解
Black-box attack:黑盒攻击:对模型不了解,对训练集不了解或了解很少
Real-word attack:在真实世界攻击。如将对抗样本打印出来,用手机拍照识别。
targeted attack:使得图像都被错分到给定类别上。
non-target attack:事先不知道需要攻击的网络细节,也不指定预测的类别,生成对抗样本来欺骗防守方的网络。
攻击方法和防御
机器之心写的很全了:综述论文:对抗攻击的12种攻击方法和15种防御方法
手把手教你生成对抗样本的Tensorflow实验↓↓↓
A Step-by-Step Guide to Synthesizing Adversarial Examples
中文:教程 | 经得住考验的「假图片」:用TensorFlow为神经网络生成对抗样本
我的文献综述作业^_^:(希望对你有用)
背景
2006 年,Geoffrey Hinton 提出了深度学习。受益于大数据的出现和大规模计算 能力的提升,深度学习已然成为最活跃的计算机研究领域之一。深度学习的多层非线 性结构使其具备强大的特征表达能力和对复杂任务的建模能力。最近几年,深度学习 的发展也带动了一系列的研究。尤其是在图像识别领域,在一些标准测试集上的试验 表明,深度模型的识别能力已经可以达到人类的水平。但是,人们还是会产生一个疑 问,对于一个非正常的输入,深度模型是否依然能够产生满意的结果。
Szegedy 等人 在 ICLR2014 发表的论文[1]中提出了对抗样本(Adversarial Examples)的概念,即在 数据集中通过故意添加细微的干扰所形成的输入样本,受干扰之后的输入导致模型以 高置信度给出一个错误的输出。他们的研究提到,很多情况下,在训练集的不同子集 上训练得到的具有不同结构的模型都会对相同的对抗样本实现误分,这意味着对抗样 本成为了训练算法的一个盲点。Nguyen 等人[2]发现面对一些人类完全无法识别的样 本(FoolingExamples),可是深度学习模型会以高置信度将它们进行分类。Kdnuggets 指出事实上深度学习对于对抗样本的脆弱性并不是深度学习所独有的,在很多的机器 学习模型中普遍存在,因此进一步研究对抗样本实际上有利于整个机器学习和深度学 习领域的进步。
目前已经有多种方法用于计算对抗样本。Akhtar 等人的调查[3]总结了超过 12 种 愚弄分类模型的攻击方法。此外,目前除了研究攻击计算机视觉中的分类/识别任务 之外,研究工作者还在研究对其他领域和方向的攻击。比如对自动编码器和生成模型、 语义分割和对象检测等的攻击。除了理解数字领域中对抗样本存在的空间外,许多研 究理解在现实世界中添加到物理对象本身的对抗样本。例如,Athalye 等人[4]表明, 甚至可以生成 3-D 打印的真实物体对抗样本去欺骗深度神经网络分类器。Gu 等人 [6] 还探讨了一个有趣的工作,即在街道标志上做扰动愚弄神经网络,神经网络将路牌的 停车标志识别为限速 45。
在数字世界中,大多数工作都集中在产生导致特定图像输入被错误分类的扰动, 但是已经证明,可以生成图像无关的对抗样本。 Moosavi-Dezfooli 等人[7]表明,给 定目标模型和数据集,可以计算单个扰动,当应用于任何输入时,都能导致很高的错 误分类。这些被称为通用对抗扰动(UAP)。 Mopuri 等人展示了他们的算法(FFF[7], GDUAP [8])来生成图像无关的扰动,这些扰动可以在不知道数据分布的情况下欺骗 目标模型。他们证明了他们精心设计的扰动可以迁移到三个不同的计算机视觉任务, 包括分类,深度估计和分割。
相关工作
许多工作[21][22][23][24][25] [26][27][28][29]研究了愚弄图像分类器的对抗扰动。 Szegedy 等人[1]首先提出对抗样本的概念,并将对抗性扰动生成描述为优化问题。 Goodfellow 等人[21]提出了一种最优的最大范数约束扰动的方法,称为“快速梯度符 号法”(FGSM),以提高计算效率。 Kurakin 等人[31]提出了一种“基本迭代方法”, 它使用 FGSM 迭代地产生扰动。 Papernot 等人[32]构建了一个对抗显示地图,以指 出可以有效影响的理想地点。Moosavi 等人的 DeepFool[33]进一步提高了对抗性扰动 的有效性。 Moosavi-Dezfooli 等人[29]发现图像分类器存在图像无关的对抗性扰动。类似于 [29],Metzen 等人[30]为语义分段任务提出了 UAP。他们扩展了 Kurakin 等人的迭代 FGSM[31]攻击,更改每个像素预测的标签。Mopuri 等人寻求数据独立的通用扰动, 不从数据分布中采样任何样本。他们提出了一个新的无数据目标的算法来生成通用对 抗扰动,称为 FFF [7]。他们后面的工作 GDUAP [8]改善了攻击的效果,并证明他们 的方法在跨计算机视觉任务上的有效性。
最近,在对目标检测器的攻击上引起了很多关注。 Lu 等人[34]试图在“停止” 标志和“面部”图像上产生对抗扰动以误导相应的检测器。Xie 等人[35]提出了一种 迭代生成对抗样本的方法来使检测器无法正确预测。Li 等人[36]提出的 R-AP 攻击算 法着重于攻击 RPN,这是深度建议网络的一个常见组成部分,在不知道检测器结构 细节的情况下普遍降低其性能。他们的后续工作[37]探讨了在背景上添加隐形扰动对 攻击物体检测器的可行性。
参考文献:
[1] Christian Szegedy. Wojciech Zaremba. Ilya Sutskever. Joan Bruna. Dumitru Erhan. Ian J. Goodfellow. and Rob Fergus. Intriguing properties of neural networks. In ICLR, 2014.
[2] Nguyen A, Yosinski J, Clune J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images[J]. 2015:427-436.
[3] Akhtar N , Mian A . Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey[J]. IEEE Access, 2018.
[4] Anish Athalye. Logan Engstrom. Andrew Ilyas. and Kevin Kwok. Synthesizing robust adversarial examples. 2018.
[5] Seyed-Mohsen Moosavi-Dezfooli. Alhussein Fawzi. Omar Fawzi. and Pascal Frossard. Universal adversarial perturbations. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[6] T. Gu, B. Dolan-Gavitt, S. Garg, BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. arXiv preprint arXiv:1708.06733, 2017.
[7] Konda Reddy Mopuri. Utsav Garg. and R. Venkatesh Babu. Fast feature fool: A data independent approach to universal adversarial perturbations. In Proceedings of the British Machine Vision Conference (BMVC).2017.
[8] Konda Reddy Mopuri. Aditya Ganeshan. and R. Venkatesh Babu. Generalizable data-free objective for crafting universal adversarial perturbations. IEEE Transactions on Pattern Analysis & Machine Intelligence. vol. PP. no. 99. pp. 1–1. 2018.
[9] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
[10] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[11] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[12] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
[13] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
[14] S. Gidaris and N. Komodakis. Object detection via a multi-region & semantic segmentation-aware cnn model. In ICCV, 2015.
[15] R. Girshick. Fast R-CNN. In ICCV, 2015.
[16] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
[17] Dai, Jifeng, Yi Li, Kaiming He and Jian Sun. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In NIPS, 2016.
[18] He, Kaiming, Georgia Gkioxari, Piotr Dollár and Ross B. Girshick. Mask R-CNN. 2017 IEEE International Conference on Computer Vision (ICCV) (2017): 2980-2988.
[19] Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott E. Reed, Cheng-Yang Fu and Alexander C. Berg. SSD: Single Shot MultiBox Detector.” In ECCV, 2016.
[20] Redmon, Joseph, Santosh Kumar Divvala, Ross B. Girshick and Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 779-788.
[21] Jonathon Shlens Ian J. Goodfellow and Christian Szegedy. Explaining and harnessing adversarial examples. In ICLR, 2015.
[22] Anh Mai Nguyen. Jason Yosinski. and Jeff Clune.Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In CVPR, 2015.
[23] Alhussein Fawzi. Seyed-Mohsen Moosavi-Dezfooli. and Pascal Frossard. Robustness of classifiers: from adversarial to random noise. In NIPS, 2016.
[24] Alhussein Fawzi. Omar Fawzi. and Pascal Frossard.Analysis of classifiers robustness to adversarial perturbations. Machine Learning. vol. 107. no. 3. pp. 481–508. 2018.
[25] Alexey Kurakin. Ian J. Goodfellow. and Samy Bengio.Adversarial machine learning at scale. CoRR. vol.abs/1611.01236. 2016.
[26] Nicolas Papernot. Patrick D. McDaniel. Somesh Jha. Matt Fredrikson. Z. Berkay Celik. and Ananthram Swami. The limitations of deep learning in adversarial settings. 2016 IEEE European Symposium on Security and Privacy (EuroSP). pp. 372–387. 2016.
[27] Jiawei Su. Danilo Vasconcellos Vargas. and Kouichi Sakurai. One pixel attack for fooling deep neural networks. CoRR. vol. abs/1710.08864. 2017.
[28] Nicholas Carlini and David A. Wagner. Towards evaluating the robustness of neural networks. 2017 IEEE Symposium on Security and Privacy (SP). pp. 39–57.2017.
[29] Seyed-Mohsen Moosavi-Dezfooli. Alhussein Fawzi. and Pascal Frossard. Deepfool: A simple and accurate method to fool deep neural networks.in CVPR, 2016.
[30] Jan Hendrik Metzen. Mummadi Chaithanya Kumar. Thomas Brox. and Volker Fischer. Universal adversarial perturbations against semantic image segmentation. In ICCV, 2017.
[31] Alexey Kurakin. Ian J. Goodfellow. and Samy Bengio.Adversarial examples in the physical world. CoRR. vol. abs/1607.02533. 2016.
[32] Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In EuroS&P, 2016.
[33] Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. Deepfool: a simple and accurate method to fool deep neural networks. In CVPR, 2016.
[34] Jiajun Lu. Hussein Sibai. and Evan Fabry. Adversarial examples that fool detectors. CoRR. vol.abs/1712.02494. 2017.
[35] Cihang Xie. Jianyu Wang. Zhishuai Zhang. Yuyin Zhou. Lingxi Xie. and Alan L. Yuille. Adversarial examples for semantic segmentation and object detection. In ICCV, 2017.
[36] Yuezun Li. Daniel Tian. Ming-Ching Chang. Xiao Bian. and Siwei Lyu. Robust adversarial perturbation on deep proposal-based models. In BMVC, 2018.
[37] Yuezun Li. Xian Bian. and Siwei Lyu. Attacking object detectors via imperceptible patches on background. CoRR. vol. abs/1809.05966. 2018.


抄袭知乎上“隅子酱”的内容