
---license: Apache License 2.0 tasks:- Domain-Specific Large Models- Object Detection---## 1. PP-ShiTuV2模型简介PP-ShiTuV2 是基于 PP-ShiTuV1 改进的一个实用轻量级通用图像识别系统,由主体检测、特征提取、向量检索三个模块构成,相比 PP-ShiTuV1 具有更高的识别精度、更强的泛化能力以及相近的推理速度*。主要针对训练数据集、特征提取两个部分进行优化,使用了更优的骨干网络、损失函数与训练策略,使得 PP-ShiTuV2 在多个实际应用场景上的检索性能有显著提升。PP-ShiTuV2模型由飞桨官方出品,是PaddleClas优化和改进的识别检索模型。 更多关于PaddleClas可以点击 https://github.com/PaddlePaddle/PaddleClas 进行了解。## 2. 模型效果及应用场景### 2.1 商品识别任务:#### 2.1.1 数据集:PP-ShiTuV2的训练数据集以 Aliproduct、GLDv2等数据集为主,详细信息可参考 [PP-ShiTuV2 实验部分](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/training/PP-ShiTu/feature_extraction.md#4-%E5%AE%9E%E9%AA%8C%E9%83%A8%E5%88%86)#### 2.1.2 模型效果速览:PP-ShiTuV2 在图片上的识别效果如下## 3. 模型如何使用### 3.1 模型推理:- 安装 PaddleClas 及其依赖包如果您的机器安装了 CUDA9、CUDA10 或 CUDA11,请运行以下命令安装 paddle```python!pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple```如果您的机器是CPU,请运行以下命令安装```python!pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple```安装 paddleclas whl包```python!pip install paddleclas```- 快速体验恭喜! 您已经成功安装了 PaddleClas,接下来快速体验图像识别效果```python# 下载并解压demo数据!wget -nc https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/rec/data/drink_dataset_v2.0.tar && tar -xf drink_dataset_v2.0.tar# 在命令行中构建索引库!paddleclas --build_gallery=True --model_name="PP-ShiTuV2" \-o IndexProcess.image_root=./drink_dataset_v2.0/gallery/ \-o IndexProcess.index_dir=./drink_dataset_v2.0/index \-o IndexProcess.data_file=./drink_dataset_v2.0/gallery/drink_label.txt# 执行图像识别命令!paddleclas --model_name="PP-ShiTuV2" --predict_type=shitu \-o Global.infer_imgs='./drink_dataset_v2.0/test_images/100.jpeg' \-o IndexProcess.index_dir='./drink_dataset_v2.0/index'```识别的结果如下所示```logppcls INFO: [{'bbox': [437, 71, 660, 728], 'rec_docs': '元气森林', 'rec_scores': 0.7740249}, {'bbox': [221, 72, 449, 701], 'rec_docs': '元气森林', 'rec_scores': 0.6950992}, {'bbox': [794, 104, 979, 652], 'rec_docs': '元气森林', 'rec_scores': 0.6305153}], filename: ./drink_dataset_v2.0/test_images/100.jpegppcls INFO: Predict complete!```如想保存识别结果为如本文档开头所示的图片,请参考 [PP-ShiTuV2 推理部署](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/models/PP-ShiTu/README.md#4-%E6%8E%A8%E7%90%86%E9%83%A8%E7%BD%B2),使用完整 PaddleClas 代码进行推理预测### 3.2 模型训练- 克隆 PaddleClas 仓库(参考 3.1模型推理 - 下载PaddleClas)- 主体检测模型的数据集准备、开始训练、模型评估等步骤,请参考 [PP-ShiTu 主体检测 文档](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/training/PP-ShiTu/mainbody_detection.md)- 特征提取模型的数据集准备、开始训练、模型评估等步骤,请参考 [PP-ShiTu 特征提取 文档](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/docs/zh_CN/training/PP-ShiTu/feature_extraction.md)## 4. 模型原理PP-ShiTu 系列识别系统,包括本文档介绍的 PP-ShiTuV2,均由3个模块串联完成整个识别过程,如下图所示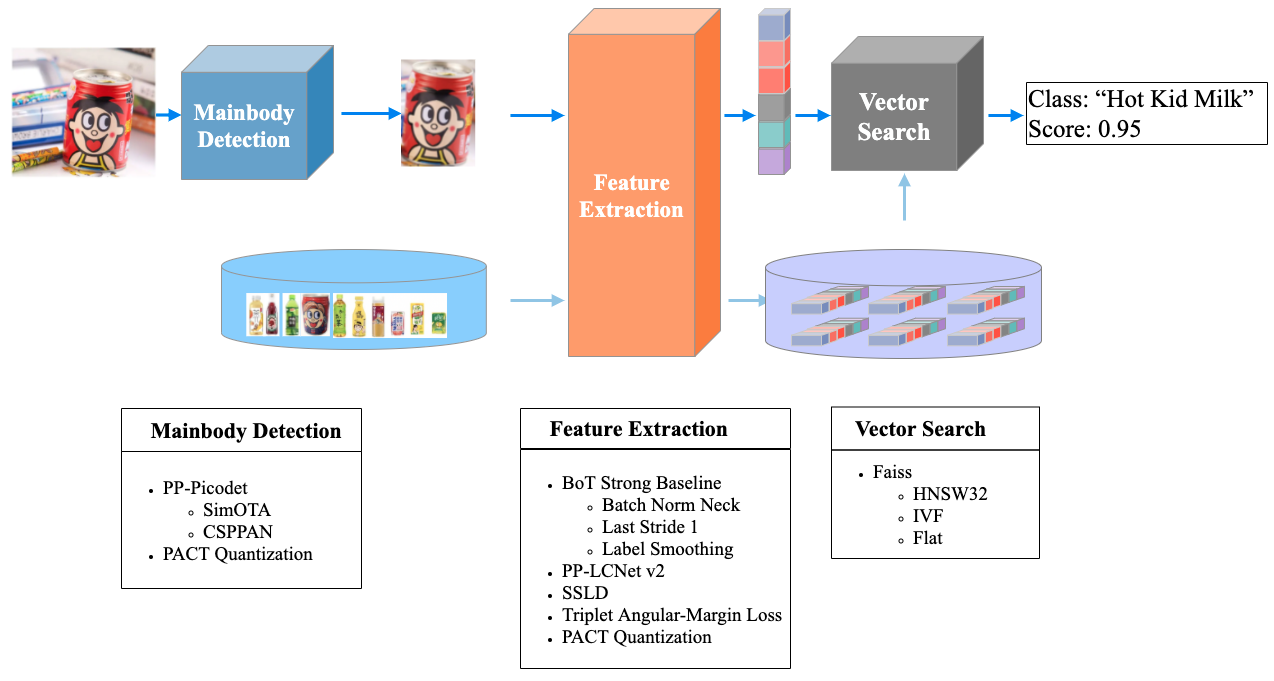- 主体检测:上图中的蓝色模块,主要负责检测出用户输入图片中可能的识别目标,进而裁剪出这些目标,过滤不重要的背景,减少背景的干扰。事实上这种保留主体,过滤背景的做法是实践中会采用的一种简单而有效的方法。- 特征提取:接收 **主体检测** 模块输出的含有目标主体的裁剪后的图片,将其输入到特征提取模型中,得到对应的特征向量,作为该图片的表示特征用于接下来的检索步骤。- 向量检索:接收 **特征提取** 模块输出的一个或多个特征向量,逐个地在向量库中检索,将检索库中最邻近(一般以相似度表示邻近程度)的向量的类别,作为检索向量的类别,最后返回检索结果。该模块不需要额外训练,安装第三方开源的faiss检索库即可使用在检索系统中,最重要的模块之一就是特征提取模型,其特征提取能力好坏直接影响检索库内向量和待检索向量的质量,因此接下来分5个部分,重点介绍 PP-ShiTuV2 所使用的特征提取模型。- Backbone Backbone 部分采用了 PP-LCNetV2_base,其在 PPLCNet_V1 的基础上,加入了包括Rep 策略、PW 卷积、Shortcut、激活函数改进、SE 模块改进等多个优化点,使得最终分类精度与 PPLCNet_x2_5 相近,且推理延时减少了40%\*。在实验过程中我们对 PPLCNetV2_base 进行了适当的改进,在保持速度基本不变的情况下,让其在识别任务中得到更高的性能,包括:去掉 PPLCNetV2_base 末尾的 ReLU 和 FC、将最后一个 stage(RepDepthwiseSeparable) 的 stride 改为1。 **注**: \*推理环境基于 Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。- Neck Neck 部分采用了 BN Neck,对 Backbone 抽取得到的特征的每个维度进行标准化操作,减少了同时优化度量学习损失函数和分类损失函数的难度,加快收敛速度的同时减少 IDLoss 和 TripletLoss 之间由于优化目标所在空间不同带来的影响。- Head Head 部分选用 FC Layer,使用分类头将 feature 转换成 logits 供后续计算分类损失(一般使用交叉熵损失,称之为CELoss或IDLoss)。- Loss Loss 部分选用 Cross entropy loss 和 TripletAngularMarginLoss,在训练时以分类损失和基于角度的三元组损失来指导网络进行优化。我们基于原始的 TripletLoss (困难三元组损失)进行了改进,将优化目标从 L2 欧几里得空间更换成余弦空间,并加入了 anchor 与 positive/negtive 之间的硬性距离约束,让训练与测试的目标更加接近,提升模型的泛化能力。详细的配置文件见 [GeneralRecognitionV2_PPLCNetV2_base.yaml](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/ppcls/configs/GeneralRecognitionV2/GeneralRecognitionV2_PPLCNetV2_base.yaml#L63-L77)。- Data Augmentation 我们考虑到实际相机拍摄时目标主体可能出现一定的旋转而不一定能保持正立状态,因此我们在数据增强中加入了适当的 [随机旋转增强](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.5/ppcls/configs/GeneralRecognitionV2/GeneralRecognitionV2_PPLCNetV2_base.yaml#L117-L120),以提升模型在真实场景中的检索能力。## 5. 注意事项PP-ShiTuV2 是在寻找在产业实践中最高性价比的图像识别方案,但考虑到不同识别场景的数据集均有各自的分布特点,以及训练时的软硬件限制,无法一次性将所有的数据集全部纳入到训练集中,经过权衡才使用了目前这套训练数据集的组合。因此推荐用户在了解自己实际业务数据集的特点之后,基于 PP-ShiTuV2 的预训练模型以及训练配置,在自己的业务数据集上进行微调甚至二次开发,以获得性能更好,更适配自己数据集的识别模型。## 6. 相关论文以及引用信息```log@article{cui2021pp, title={PP-LCNet: A Lightweight CPU Convolutional Neural Network}, author={Cui, Cheng and Gao, Tingquan and Wei, Shengyu and Du, Yuning and Guo, Ruoyu and Dong, Shuilong and Lu, Bin and Zhou, Ying and Lv, Xueying and Liu, Qiwen and others}, journal={arXiv preprint arXiv:2109.15099}, year={2021}}@InProceedings{Luo_2019_CVPR_Workshops, author = {Luo, Hao and Gu, Youzhi and Liao, Xingyu and Lai, Shenqi and Jiang, Wei}, title = {Bag of Tricks and a Strong Baseline for Deep Person Re-Identification}, booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, month = {June}, year = {2019}}@ARTICLE{Luo_2019_Strong_TMM, author={H. {Luo} and W. {Jiang} and Y. {Gu} and F. {Liu} and X. {Liao} and S. {Lai} and J. {Gu}}, journal={IEEE Transactions on Multimedia}, title={A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification}, year={2019}, pages={1-1}, doi={10.1109/TMM.2019.2958756}, ISSN={1941-0077},}```请点击[此处](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576)查看本环境基本用法. <br>Please click [here ](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576) for more detailed instructions.