
---license: Apache License 2.0 tasks:- Object Detection- Image-to-Text---# 一、PP-OCRv5简介**PP-OCRv5** 是PP-OCR新一代文字识别解决方案,该方案聚焦于多场景、多文字类型的文字识别。在文字类型方面,PP-OCRv5支持简体中文、中文拼音、繁体中文、英文、日文5大主流文字类型,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。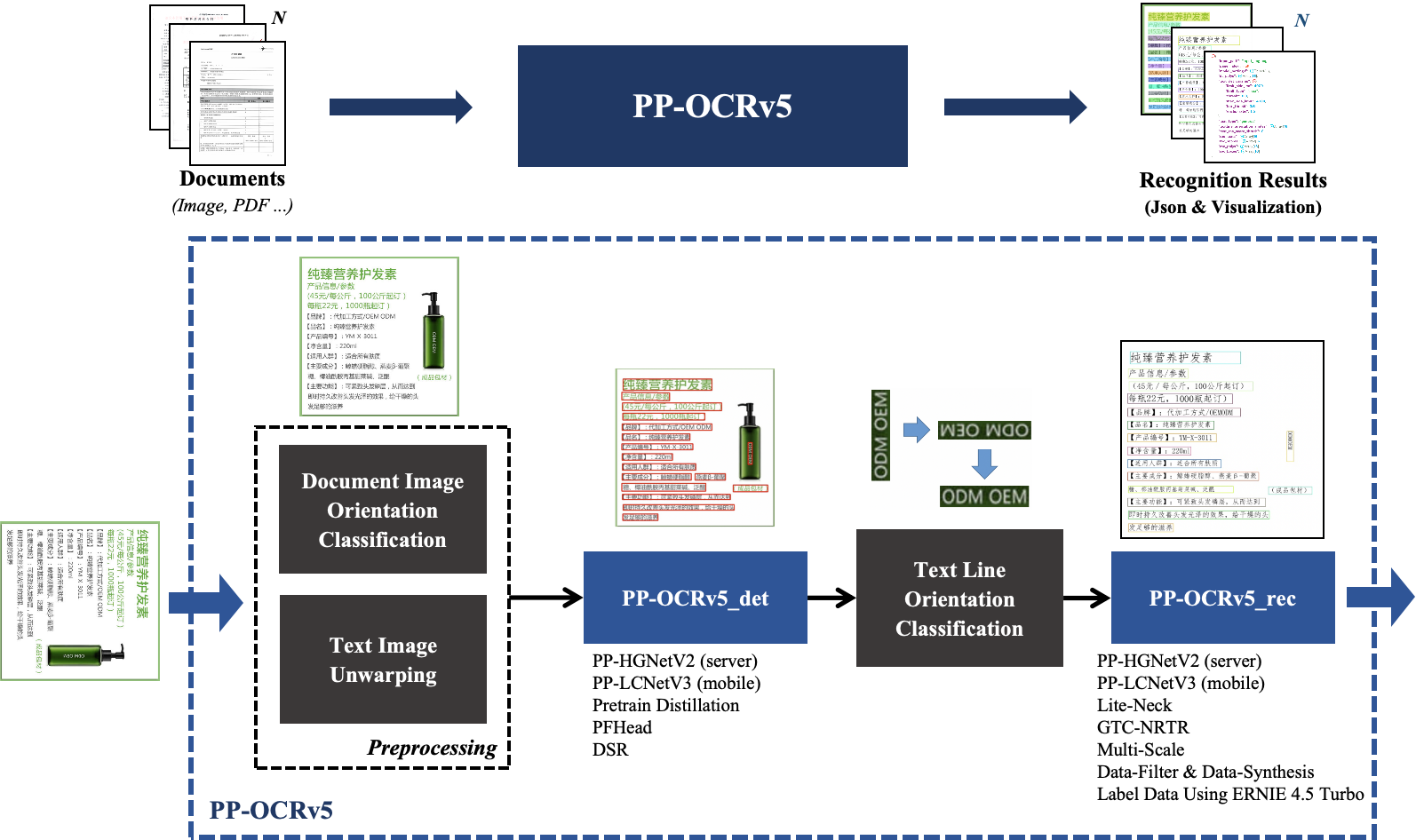# 二、关键指标### 1. 文本检测指标<table> <thead> <tr> <th>模型</th> <th>手写中文</th> <th>手写英文</th> <th>印刷中文</th> <th>印刷英文</th> <th>繁体中文</th> <th>古籍文本</th> <th>日文</th> <th>通用场景</th> <th>拼音</th> <th>旋转</th> <th>扭曲</th> <th>艺术字</th> <th>平均</th> </tr> </thead> <tbody> <tr> <td><b>PP-OCRv5_server_det</b></td> <td><b>0.803</b></td> <td><b>0.841</b></td> <td><b>0.945</b></td> <td><b>0.917</b></td> <td><b>0.815</b></td> <td><b>0.676</b></td> <td><b>0.772</b></td> <td><b>0.797</b></td> <td><b>0.671</b></td> <td><b>0.8</b></td> <td><b>0.876</b></td> <td><b>0.673</b></td> <td><b>0.827</b></td> </tr> <tr> <td>PP-OCRv4_server_det</td> <td>0.706</td> <td>0.249</td> <td>0.888</td> <td>0.690</td> <td>0.759</td> <td>0.473</td> <td>0.685</td> <td>0.715</td> <td>0.542</td> <td>0.366</td> <td>0.775</td> <td>0.583</td> <td>0.662</td> </tr> <tr> <td><b>PP-OCRv5_mobile_det</b></td> <td><b>0.744</b></td> <td><b>0.777</b></td> <td><b>0.905</b></td> <td><b>0.910</b></td> <td><b>0.823</b></td> <td><b>0.581</b></td> <td><b>0.727</b></td> <td><b>0.721</b></td> <td><b>0.575</b></td> <td><b>0.647</b></td> <td><b>0.827</b></td> <td>0.525</td> <td><b>0.770</b></td> </tr> <tr> <td>PP-OCRv4_mobile_det</td> <td>0.583</td> <td>0.369</td> <td>0.872</td> <td>0.773</td> <td>0.663</td> <td>0.231</td> <td>0.634</td> <td>0.710</td> <td>0.430</td> <td>0.299</td> <td>0.715</td> <td><b>0.549</b></td> <td>0.624</td> </tr> </tbody></table>对比PP-OCRv4,PP-OCRv5在所有检测场景下均有明显提升,尤其在手写、古籍、日文检测能力上表现更优。### 2. 文本识别指标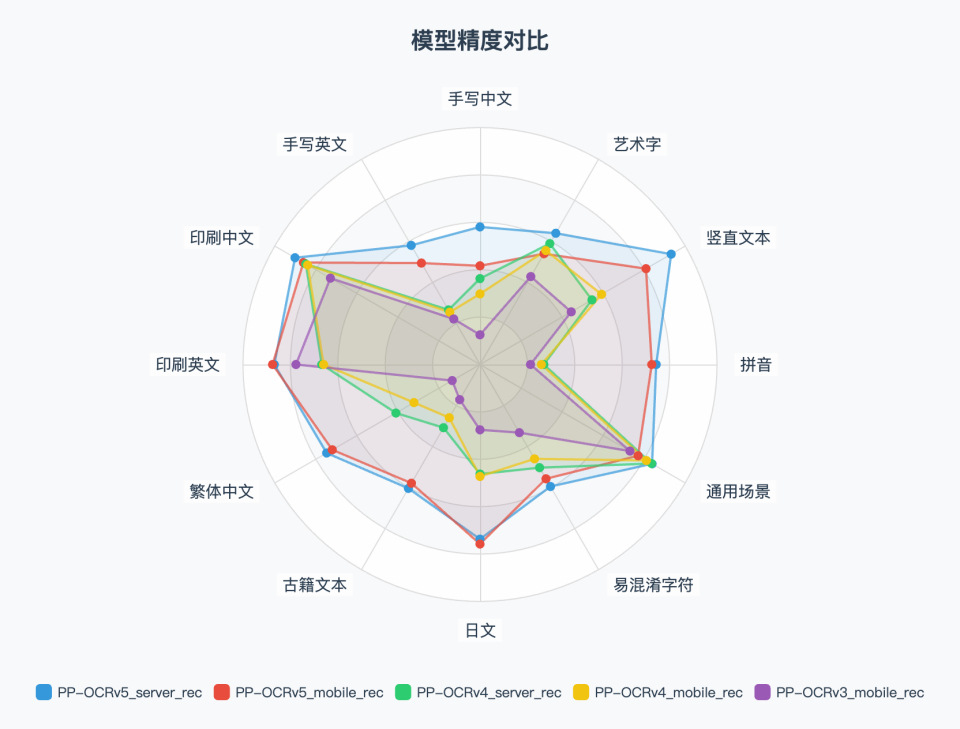<table> <thead> <tr> <th>评估集类别</th> <th>手写中文</th> <th>手写英文</th> <th>印刷中文</th> <th>印刷英文</th> <th>繁体中文</th> <th>古籍文本</th> <th>日文</th> <th>易混淆字符</th> <th>通用场景</th> <th>拼音</th> <th>竖直文本</th> <th>艺术字</th> <th>加权平均</th> </tr> </thead> <tbody> <tr> <td>PP-OCRv5_server_rec</td> <td><b>0.5807</b></td> <td><b>0.5806</b></td> <td><b>0.9013</b></td> <td><b>0.8679</b></td> <td><b>0.7472</b></td> <td><b>0.6039</b></td> <td><b>0.7372</b></td> <td><b>0.5946</b></td> <td><b>0.8384</b></td> <td><b>0.7435</b></td> <td><b>0.9314</b></td> <td><b>0.6397</b></td> <td><b>0.8401</b></td> </tr> <tr> <td>PP-OCRv4_server_rec</td> <td>0.3626</td> <td>0.2661</td> <td>0.8486</td> <td>0.6677</td> <td>0.4097</td> <td>0.3080</td> <td>0.4623</td> <td>0.5028</td> <td>0.8362</td> <td>0.2694</td> <td>0.5455</td> <td>0.5892</td> <td>0.5735</td> </tr> <tr> <td>PP-OCRv5_mobile_rec</td> <td><b>0.4166</b></td> <td><b>0.4944</b></td> <td><b>0.8605</b></td> <td><b>0.8753</b></td> <td><b>0.7199</b></td> <td><b>0.5786</b></td> <td><b>0.7577</b></td> <td><b>0.5570</b></td> <td>0.7703</td> <td><b>0.7248</b></td> <td><b>0.8089</b></td> <td>0.5398</td> <td><b>0.8015</b></td> </tr> <tr> <td>PP-OCRv4_mobile_rec</td> <td>0.2980</td> <td>0.2550</td> <td>0.8398</td> <td>0.6598</td> <td>0.3218</td> <td>0.2593</td> <td>0.4724</td> <td>0.4599</td> <td><b>0.8106</b></td> <td>0.2593</td> <td>0.5924</td> <td><b>0.5555</b></td> <td>0.5301</td> </tr> </tbody></table>单模型即可覆盖多语言和多类型文本,识别精度大幅领先前代产品和主流开源方案。# 三、PP-OCRv5 Demo示例[更多示例](https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/doc_images/PP-OCRv5/algorithm_ppocrv5_demo.pdf)# 四、使用方式在本地使用 PP-OCRv5 产线前,请确保您已经按照[安装教程](https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/version3.x/installation.md)完成了wheel包安装。安装完成后,可以在本地使用命令行体验或 Python 集成。## 1. 命令行方式一行命令即可快速体验OCR产线效果。运行以下代码前,请您下载[示例图片](https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png)到本地:```bash# 默认使用 PP-OCRv5 模型paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \ --use_doc_orientation_classify False \ --use_doc_unwarping False \ --use_textline_orientation False \ --save_path ./output \ --device gpu:0 # 通过 --ocr_version 指定 PP-OCR 其他版本paddleocr ocr -i ./general_ocr_002.png --ocr_version PP-OCRv4```<details><summary><b>命令行支持更多参数设置,点击展开以查看命令行参数的详细说明</b></summary><table><thead><tr><th>参数</th><th>参数说明</th><th>参数类型</th><th>默认值</th></tr></thead><tbody><tr><td><code>input</code></td><td>待预测数据,必填。如图像文件或者PDF文件的本地路径:<code>/root/data/img.jpg</code>;<b>如URL链接</b>,如图像文件或PDF文件的网络URL:<a href="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png">示例</a>;<b>如本地目录</b>,该目录下需包含待预测图像,如本地路径:<code>/root/data/</code>(当前不支持目录中包含PDF文件的预测,PDF文件需要指定到具体文件路径)。</td><td><code>str</code></td><td></td></tr><tr><td><code>save_path</code></td><td>指定推理结果文件保存的路径。如果不设置,推理结果将不会保存到本地。</td><td><code>str</code></td><td></td></tr><tr><td><code>doc_orientation_classify_model_name</code></td><td>文档方向分类模型的名称。如果不设置,将会使用产线默认模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>doc_orientation_classify_model_dir</code></td><td>文档方向分类模型的目录路径。如果不设置,将会下载官方模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>doc_unwarping_model_name</code></td><td>文本图像矫正模型的名称。如果不设置,将会使用产线默认模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>doc_unwarping_model_dir</code></td><td>文本图像矫正模型的目录路径。如果不设置,将会下载官方模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_detection_model_name</code></td><td>文本检测模型的名称。如果不设置,将会使用产线默认模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_detection_model_dir</code></td><td>文本检测模型的目录路径。如果不设置,将会下载官方模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_line_orientation_model_name</code></td><td>文本行方向模型的名称。如果不设置,将会使用产线默认模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_line_orientation_model_dir</code></td><td>文本行方向模型的目录路径。如果不设置,将会下载官方模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_line_orientation_batch_size</code></td><td>文本行方向模型的批处理大小。如果不设置,将默认设置批处理大小为<code>1</code>。</td><td><code>int</code></td><td></td></tr><tr><td><code>text_recognition_model_name</code></td><td>文本识别模型的名称。如果不设置,将会使用产线默认模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_recognition_model_dir</code></td><td>文本识别模型的目录路径。如果不设置,将会下载官方模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_recognition_batch_size</code></td><td>文本识别模型的批处理大小。如果不设置,将默认设置批处理大小为<code>1</code>。</td><td><code>int</code></td><td></td></tr><tr><td><code>use_doc_orientation_classify</code></td><td>是否加载并使用文档方向分类功能。如果不设置,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td></td></tr><tr><td><code>use_doc_unwarping</code></td><td>是否加载并使用文本图像矫正功能。如果不设置,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td></td></tr><tr><td><code>use_textline_orientation</code></td><td>是否加载并使用文本行方向功能。如果不设置,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td></td></tr><tr><td><code>text_det_limit_side_len</code></td><td>文本检测的最大边长度限制。大于 <code>0</code> 的任意整数。如果不设置,将默认使用产线初始化的该参数值,初始化为 <code>960</code>。</td><td><code>int</code></td><td></td></tr><tr><td><code>text_det_limit_type</code></td><td>文本检测的边长度限制类型。支持 <code>min</code> 和 <code>max</code>,<code>min</code> 表示保证图像最短边不小于 <code>det_limit_side_len</code>,<code>max</code> 表示保证图像最长边不大于 <code>limit_side_len</code>。如果不设置,将默认使用产线初始化的该参数值,初始化为 <code>max</code>。</td><td><code>str</code></td><td></td></tr><tr><td><code>text_det_thresh</code></td><td>文本检测像素阈值,输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点。大于<code>0</code>的任意浮点数。如果不设置,将默认使用产线初始化的该参数值 <code>0.3</code>。</td><td><code>float</code></td><td></td></tr><tr><td><code>text_det_box_thresh</code></td><td>文本检测框阈值,检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域。大于 <code>0</code> 的任意浮点数。如果不设置,将默认使用产线初始化的该参数值 <code>0.6</code>。</td><td><code>float</code></td><td></td></tr><tr><td><code>text_det_unclip_ratio</code></td><td>文本检测扩张系数,使用该方法对文字区域进行扩张,该值越大,扩张的面积越大。大于<code>0</code>的任意浮点数。如果不设置,将默认使用产线初始化的该参数值 <code>2.0</code>。</td><td><code>float</code></td><td></td></tr><tr><td><code>text_det_input_shape</code></td><td>文本检测的输入形状,您可以设置3个值代表C,H,W。</td><td><code>int</code></td><td></td></tr><tr><td><code>text_rec_score_thresh</code></td><td>文本识别阈值,得分大于该阈值的文本结果会被保留。大于<code>0</code>的任意浮点数。如果不设置,将默认使用产线初始化的该参数值 <code>0.0</code>。即不设阈值。</td><td><code>float</code></td><td></td></tr><tr><td><code>text_rec_input_shape</code></td><td>文本识别的输入形状。</td><td><code>tuple</code></td><td></td></tr><tr><td><code>lang</code></td><td>使用指定语言的 OCR 模型。<ul><li><b>ch</b>:中文;<li><b>en</b>:英文;<li><b>korean</b>:韩文;<li><b>japan</b>:日文;<li><b>chinese_cht</b>:繁体中文;<li><b>te</b>:泰卢固文;<li><b>ka</b>:卡纳达文;<li><b>ta</b>:泰米尔文;</ul>如果不设置,将默认使用<code>ch</code>。</td><td><code>str</code></td><td></td></tr><tr><td><code>ocr_version</code></td><td>OCR 版本。<ul><li><b>PP-OCRv5</b>:使用<code>PP-OCRv5</code>系列模型;<li><b>PP-OCRv4</b>:使用<code>PP-OCRv4</code>系列模型;<li><b>PP-OCRv3</b>:使用<code>PP-OCRv3</code>系列模型;</ul>如果不设置,将默认使用<code>PP-OCRv5</code>系列模型。</td><td><code>str</code></td><td></td></tr><tr><td><code>det_model_dir</code></td><td>已废弃,请参考<code>text_detection_model_dir</code>,且与新的参数不能同时指定。</td><td><code>str</code></td><td></td></tr><tr><td><code>det_limit_side_len</code></td><td>已废弃,请参考<code>text_det_limit_side_len</code>,且与新的参数不能同时指定。</td><td><code>int</code></td><td></td></tr><tr><td><code>det_limit_type</code></td><td>已废弃,请参考<code>text_det_limit_type</code>,且与新的参数不能同时指定。</td><td><code>str</code></td><td></td></tr><tr><td><code>det_db_thresh</code></td><td>已废弃,请参考<code>text_det_thresh</code>,且与新的参数不能同时指定。</td><td><code>float</code></td><td></td></tr><tr><td><code>det_db_box_thresh</code></td><td>已废弃,请参考<code>text_det_box_thresh</code>,且与新的参数不能同时指定。</td><td><code>float</code></td><td></td></tr><tr><td><code>det_db_unclip_ratio</code></td><td>已废弃,请参考<code>text_det_unclip_ratio</code>,且与新的参数不能同时指定。</td><td><code>float</code></td><td></td></tr><tr><td><code>rec_model_dir</code></td><td>已废弃,请参考<code>text_recognition_model_dir</code>,且与新的参数不能同时指定。</td><td><code>str</code></td><td></td></tr><tr><td><code>rec_batch_num</code></td><td>已废弃,请参考<code>text_recognition_batch_size</code>,且与新的参数不能同时指定。</td><td><code>int</code></td><td></td></tr><tr><td><code>use_angle_cls</code></td><td>已废弃,请参考<code>use_textline_orientation</code>,且与新的参数不能同时指定。</td><td><code>bool</code></td><td></td></tr><tr><td><code>cls_model_dir</code></td><td>已废弃,请参考<code>text_line_orientation_model_dir</code>,且与新的参数不能同时指定。</td><td><code>str</code></td><td></td></tr><tr><td><code>cls_batch_num</code></td><td>已废弃,请参考<code>text_line_orientation_batch_size</code>,且与新的参数不能同时指定。</td><td><code>int</code></td><td></td></tr><tr><td><code>device</code></td><td>用于推理的设备。支持指定具体卡号。<ul><li><b>CPU</b>:如 <code>cpu</code> 表示使用 CPU 进行推理;</li><li><b>GPU</b>:如 <code>gpu:0</code> 表示使用第 1 块 GPU 进行推理;</li><li><b>NPU</b>:如 <code>npu:0</code> 表示使用第 1 块 NPU 进行推理;</li><li><b>XPU</b>:如 <code>xpu:0</code> 表示使用第 1 块 XPU 进行推理;</li><li><b>MLU</b>:如 <code>mlu:0</code> 表示使用第 1 块 MLU 进行推理;</li><li><b>DCU</b>:如 <code>dcu:0</code> 表示使用第 1 块 DCU 进行推理;</li></ul>如果不设置,将默认使用产线初始化的该参数值,初始化时,会优先使用本地的 GPU 0号设备,如果没有,则使用 CPU 设备。</td><td><code>str</code></td><td></td></tr><tr><td><code>enable_hpi</code></td><td>是否启用高性能推理。</td><td><code>bool</code></td><td><code>False</code></td></tr><tr><td><code>use_tensorrt</code></td><td>是否使用 TensorRT 进行推理加速。</td><td><code>bool</code></td><td><code>False</code></td></tr><tr><td><code>min_subgraph_size</code></td><td>最小子图大小,用于优化模型子图的计算。</td><td><code>int</code></td><td><code>3</code></td></tr><tr><td><code>precision</code></td><td>计算精度,如 fp32、fp16。</td><td><code>str</code></td><td><code>fp32</code></td></tr><tr><td><code>enable_mkldnn</code></td><td>是否启用 MKL-DNN 加速库。如果不设置,将默认启用。</td><td><code>bool</code></td><td></td></tr><tr><td><code>cpu_threads</code></td><td>在 CPU 上进行推理时使用的线程数。</td><td><code>int</code></td><td><code>8</code></td></tr><tr><td><code>paddlex_config</code></td><td>PaddleX产线配置文件路径。</td><td><code>str</code></td><td></td></tr></tbody></table></details><br />运行结果会被打印到终端上:```bash{'res': {'input_path': './general_ocr_002.png', 'page_index': None, 'model_settings': {'use_doc_preprocessor': True, 'use_textline_orientation': False}, 'doc_preprocessor_res': {'input_path': None, 'page_index': None, 'model_settings': {'use_doc_orientation_classify': False, 'use_doc_unwarping': False}, 'angle': -1}, 'dt_polys': array([[[ 3, 10], ..., [ 4, 30]], ..., [[ 99, 456], ..., [ 99, 479]]], dtype=int16), 'text_det_params': {'limit_side_len': 736, 'limit_type': 'min', 'thresh': 0.3, 'max_side_limit': 4000, 'box_thresh': 0.6, 'unclip_ratio': 1.5}, 'text_type': 'general', 'textline_orientation_angles': array([-1, ..., -1]), 'text_rec_score_thresh': 0.0, 'rec_texts': ['www.997700', '', 'Cm', '登机牌', 'BOARDING', 'PASS', 'CLASS', '序号SERIAL NO.', '座位号', 'SEAT NO.', '航班FLIGHT', '日期DATE', '舱位', '', 'W', '035', '12F', 'MU2379', '03DEc', '始发地', 'FROM', '登机口', 'GATE', '登机时间BDT', '目的地TO', '福州', 'TAIYUAN', 'G11', 'FUZHOU', '身份识别IDNO.', '姓名NAME', 'ZHANGQIWEI', '票号TKT NO.', '张祺伟', '票价FARE', 'ETKT7813699238489/1', '登机口于起飞前10分钟关闭 GATESCL0SE10MINUTESBEFOREDEPARTURETIME'], 'rec_scores': array([0.67634439, ..., 0.97416091]), 'rec_polys': array([[[ 3, 10], ..., [ 4, 30]], ..., [[ 99, 456], ..., [ 99, 479]]], dtype=int16), 'rec_boxes': array([[ 3, ..., 30], ..., [ 99, ..., 479]], dtype=int16)}}```若指定了`save_path`,则会保存可视化结果在`save_path`下。可视化结果如下:## 2. Python脚本方式集成命令行方式是为了快速体验查看效果,一般来说,在项目中,往往需要通过代码集成,您可以通过几行代码即可完成产线的快速推理,推理代码如下:```pythonfrom paddleocr import PaddleOCRocr = PaddleOCR( use_doc_orientation_classify=False, # 通过 use_doc_orientation_classify 参数指定不使用文档方向分类模型 use_doc_unwarping=False, # 通过 use_doc_unwarping 参数指定不使用文本图像矫正模型 use_textline_orientation=False, # 通过 use_textline_orientation 参数指定不使用文本行方向分类模型)# ocr = PaddleOCR(lang="en") # 通过 lang 参数来使用英文模型# ocr = PaddleOCR(ocr_version="PP-OCRv4") # 通过 ocr_version 参数来使用 PP-OCR 其他版本# ocr = PaddleOCR(device="gpu") # 通过 device 参数使得在模型推理时使用 GPU# ocr = PaddleOCR(# text_detection_model_name="PP-OCRv5_server_det",# text_recognition_model_name="PP-OCRv5_server_rec",# use_doc_orientation_classify=False,# use_doc_unwarping=False,# use_textline_orientation=False,# ) # 更换 PP-OCRv5_server 模型result = ocr.predict("./general_ocr_002.png")for res in result: res.print() res.save_to_img("output") res.save_to_json("output")```在上述 Python 脚本中,执行了如下几个步骤:<details><summary>(1)通过 <code>PaddleOCR()</code> 实例化 OCR 产线对象,具体参数说明如下:</summary><table> <thead> <tr> <th>参数</th> <th>参数说明</th> <th>参数类型</th> <th>默认值</th> </tr> </thead> <tbody><tr><td><code>doc_orientation_classify_model_name</code></td><td>文档方向分类模型的名称。如果设置为<code>None</code>,将会使用产线默认模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>doc_orientation_classify_model_dir</code></td><td>文档方向分类模型的目录路径。如果设置为<code>None</code>,将会下载官方模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>doc_unwarping_model_name</code></td><td>文本图像矫正模型的名称。如果设置为<code>None</code>,将会使用产线默认模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>doc_unwarping_model_dir</code></td><td>文本图像矫正模型的目录路径。如果设置为<code>None</code>,将会下载官方模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_detection_model_name</code></td><td>文本检测模型的名称。如果设置为<code>None</code>,将会使用产线默认模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_detection_model_dir</code></td><td>文本检测模型的目录路径。如果设置为<code>None</code>,将会下载官方模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_line_orientation_model_name</code></td><td>文本行方向模型的名称。如果设置为<code>None</code>,将会使用产线默认模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_line_orientation_model_dir</code></td><td>文本行方向模型的目录路径。如果设置为<code>None</code>,将会下载官方模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_line_orientation_batch_size</code></td><td>文本行方向模型的批处理大小。如果设置为<code>None</code>,将默认设置批处理大小为<code>1</code>。</td><td><code>int</code></td><td><code>None</code></td></tr><tr><td><code>text_recognition_model_name</code></td><td>文本识别模型的名称。如果设置为<code>None</code>,将会使用产线默认模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_recognition_model_dir</code></td><td>文本识别模型的目录路径。如果设置为<code>None</code>,将会下载官方模型。</td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_recognition_batch_size</code></td><td>文本识别模型的批处理大小。如果设置为<code>None</code>,将默认设置批处理大小为<code>1</code>。</td><td><code>int</code></td><td><code>None</code></td></tr><tr><td><code>use_doc_orientation_classify</code></td><td>是否加载并使用文档方向分类功能。如果设置为<code>None</code>,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td><code>None</code></td></tr><tr><td><code>use_doc_unwarping</code></td><td>是否加载并使用文本图像矫正功能。如果设置为<code>None</code>,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td><code>None</code></td></tr><tr><td><code>use_textline_orientation</code></td><td>是否加载并使用文本行方向功能。如果设置为<code>None</code>,将默认使用产线初始化的该参数值,初始化为<code>True</code>。</td><td><code>bool</code></td><td><code>None</code></td></tr><tr><td><code>text_det_limit_side_len</code></td><td>文本检测的最大边长度限制。<ul><li><b>int</b>:大于 <code>0</code> 的任意整数;</li><li><b>None</b>:如果设置为<code>None</code>, 将默认使用产线初始化的该参数值,初始化为 <code>960</code>。</li></ur></td><td><code>int</code></td><td><code>None</code></td></tr><tr><td><code>text_det_limit_type</code></td><td>文本检测的边长度限制类型。<ul><li><b>str</b>:支持 <code>min</code> 和 <code>max</code>,<code>min</code> 表示保证图像最短边不小于 <code>det_limit_side_len</code>,<code>max</code> 表示保证图像最长边不大于 <code>limit_side_len</code>;</li><li><b>None</b>:如果设置为<code>None</code>, 将默认使用产线初始化的该参数值,初始化为 <code>max</code>。</li></ur></td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>text_det_thresh</code></td><td>文本检测像素阈值,输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点。<ul><li><b>float</b>:大于<code>0</code>的任意浮点数;<li><b>None</b>:如果设置为<code>None</code>, 将默认使用产线初始化的该参数值 <code>0.3</code>。</li></td><td><code>float</code></td><td><code>None</code></td></tr><tr><td><code>text_det_box_thresh</code></td><td>文本检测框阈值,检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域。<ul><li><b>float</b>:大于<code>0</code>的任意浮点数;<li><b>None</b>:如果设置为<code>None</code>将默认使用产线初始化的该参数值 <code>0.6</code>。</td><td><code>float</code></td><td><code>None</code></td></tr><tr><td><code>text_det_unclip_ratio</code></td><td>文本检测扩张系数,使用该方法对文字区域进行扩张,该值越大,扩张的面积越大。<ul><li><b>float</b>:大于<code>0</code>的任意浮点数;<li><b>None</b>:如果设置为<code>None</code>,将默认使用产线初始化的该参数值 <code>2.0</code>。</ur></td><td><code>float</code></td><td><code>None</code></td></tr><tr><td><code>text_det_input_shape</code></td><td>文本检测的输入形状。</td><td><code>tuple</code></td><td><code>None</code></td></tr><tr><td><code>text_rec_score_thresh</code></td><td>文本识别阈值,得分大于该阈值的文本结果会被保留。<ul><li><b>float</b>:大于<code>0</code>的任意浮点数;<li><b>None</b>:如果设置为<code>None</code>,将默认使用产线初始化的该参数值 <code>0.0</code>,即不设阈值。</ur></td><td><code>float</code></td><td><code>None</code></td></tr><tr><td><code>text_rec_input_shape</code></td><td>文本识别的输入形状。</td><td><code>tuple</code></td><td><code>None</code></td></tr><tr><td><code>lang</code></td><td>使用指定语言的 OCR 模型。<ul><li><b>ch</b>:中文;<li><b>en</b>:英文;<li><b>korean</b>:韩文;<li><b>japan</b>:日文;<li><b>chinese_cht</b>:繁体中文;<li><b>te</b>:泰卢固文;<li><b>ka</b>:卡纳达文;<li><b>ta</b>:泰米尔文;<li><b>None</b>:如果设置为<code>None</code>,将默认使用<code>ch</code>。</ur></td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>ocr_version</code></td><td>OCR 版本。<ul><li><b>PP-OCRv5</b>:使用<code>PP-OCRv5</code>系列模型;<li><b>PP-OCRv4</b>:使用<code>PP-OCRv4</code>系列模型;<li><b>PP-OCRv3</b>:使用<code>PP-OCRv3</code>系列模型;<li><b>None</b>:如果设置为<code>None</code>, 将默认使用<code>PP-OCRv5</code>系列模型。</ur></td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>device</code></td><td>用于推理的设备。支持指定具体卡号。<ul><li><b>CPU</b>:如 <code>cpu</code> 表示使用 CPU 进行推理;</li><li><b>GPU</b>:如 <code>gpu:0</code> 表示使用第 1 块 GPU 进行推理;</li><li><b>NPU</b>:如 <code>npu:0</code> 表示使用第 1 块 NPU 进行推理;</li><li><b>XPU</b>:如 <code>xpu:0</code> 表示使用第 1 块 XPU 进行推理;</li><li><b>MLU</b>:如 <code>mlu:0</code> 表示使用第 1 块 MLU 进行推理;</li><li><b>DCU</b>:如 <code>dcu:0</code> 表示使用第 1 块 DCU 进行推理;</li><li><b>None</b>:如果设置为<code>None</code>,将默认使用产线初始化的该参数值,初始化时,会优先使用本地的 GPU 0号设备,如果没有,则使用 CPU 设备。</ur></td><td><code>str</code></td><td><code>None</code></td></tr><tr><td><code>enable_hpi</code></td><td>是否启用高性能推理。</td><td><code>bool</code></td><td><code>False</code></td></tr><tr><td><code>use_tensorrt</code></td><td>是否使用 TensorRT 进行推理加速。</td><td><code>bool</code></td><td><code>False</code></td></tr><tr><td><code>min_subgraph_size</code></td><td>最小子图大小,用于优化模型子图的计算。</td><td><code>int</code></td><td><code>3</code></td></tr><tr><td><code>precision</code></td><td>计算精度,如 fp32、fp16。</td><td><code>str</code></td><td><code>"fp32"</code></td></tr><tr><td><code>enable_mkldnn</code></td><td>是否启用 MKL-DNN 加速库。如果设置为<code>None</code>,将默认启用。</td><td><code>bool</code></td><td><code>None</code></td></tr><tr><td><code>cpu_threads</code></td><td>在 CPU 上进行推理时使用的线程数。</td><td><code>int</code></td><td><code>8</code></td></tr><tr><td><code>paddlex_config</code></td><td>PaddleX产线配置文件路径。</td><td><code>str</code></td><td><code>None</code></td></tr></tbody></table></details><details><summary>(2)调用 OCR 产线对象的 <code>predict()</code> 方法进行推理预测,该方法会返回一个结果列表。另外,产线还提供了 <code>predict_iter()</code> 方法。两者在参数接受和结果返回方面是完全一致的,区别在于 <code>predict_iter()</code> 返回的是一个 <code>generator</code>,能够逐步处理和获取预测结果,适合处理大型数据集或希望节省内存的场景。可以根据实际需求选择使用这两种方法中的任意一种。以下是 <code>predict()</code> 方法的参数及其说明:</summary><table><thead><tr><th>参数</th><th>参数说明</th><th>参数类型</th><th>默认值</th></tr></thead><tr><td><code>input</code></td><td>待预测数据,支持多种输入类型,必填。<ul><li><b>Python Var</b>:如 <code>numpy.ndarray</code> 表示的图像数据;</li><li><b>str</b>:如图像文件或者PDF文件的本地路径:<code>/root/data/img.jpg</code>;<b>如URL链接</b>,如图像文件或PDF文件的网络URL:<a href="https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png">示例</a>;<b>如本地目录</b>,该目录下需包含待预测图像,如本地路径:<code>/root/data/</code>(当前不支持目录中包含PDF文件的预测,PDF文件需要指定到具体文件路径);</li><li><b>List</b>:列表元素需为上述类型数据,如<code>[numpy.ndarray, numpy.ndarray]</code>,<code>["/root/data/img1.jpg", "/root/data/img2.jpg"]</code>,<code>["/root/data1", "/root/data2"]。</code></li></ul></td><td><code>Python Var|str|list</code></td><td></td></tr><tr><td><code>use_doc_orientation_classify</code></td><td>是否在推理时使用文档方向分类模块。</td><td><code>bool</code></td><td><code>None</code></td></tr><tr><td><code>use_doc_unwarping</code></td><td>是否在推理时使用文本图像矫正模块。</td><td><code>bool</code></td><td><code>None</code></td></tr><td><code>use_textline_orientation</code></td><td>是否在推理时使用文本行方向分类模块。</td><td><code>bool</code></td><td><code>None</code></td></tr><td><code>text_det_limit_side_len</code></td><td>与实例化时的参数相同。</td><td><code>int</code></td><td><code>None</code></td></tr><td><code>text_det_limit_type</code></td><td>与实例化时的参数相同。</td><td><code>str</code></td><td><code>None</code></td></tr><td><code>text_det_thresh</code></td><td>与实例化时的参数相同。</td><td><code>float</code></td><td><code>None</code></td></tr><td><code>text_det_box_thresh</code></td><td>与实例化时的参数相同。</td><td><code>float</code></td><td><code>None</code></td></tr><td><code>text_det_unclip_ratio</code></td><td>与实例化时的参数相同。</td><td><code>float</code></td><td><code>None</code></td></tr><td><code>text_rec_score_thresh</code></td><td>与实例化时的参数相同。</td><td><code>float</code></td><td><code>None</code></td></table></details><details><summary>(3)对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为<code>json</code>文件的操作:</summary><table><thead><tr><th>方法</th><th>方法说明</th><th>参数</th><th>参数类型</th><th>参数说明</th><th>默认值</th></tr></thead><tr><td rowspan="3"><code>print()</code></td><td rowspan="3">打印结果到终端</td><td><code>format_json</code></td><td><code>bool</code></td><td>是否对输出内容进行使用 <code>JSON</code> 缩进格式化。</td><td><code>True</code></td></tr><tr><td><code>indent</code></td><td><code>int</code></td><td>指定缩进级别,以美化输出的 <code>JSON</code> 数据,使其更具可读性,仅当 <code>format_json</code> 为 <code>True</code> 时有效。</td><td>4</td></tr><tr><td><code>ensure_ascii</code></td><td><code>bool</code></td><td>控制是否将非 <code>ASCII</code> 字符转义为 <code>Unicode</code>。设置为 <code>True</code> 时,所有非 <code>ASCII</code> 字符将被转义;<code>False</code> 则保留原始字符,仅当<code>format_json</code>为<code>True</code>时有效。</td><td><code>False</code></td></tr><tr><td rowspan="3"><code>save_to_json()</code></td><td rowspan="3">将结果保存为json格式的文件</td><td><code>save_path</code></td><td><code>str</code></td><td>保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致。</td><td>无</td></tr><tr><td><code>indent</code></td><td><code>int</code></td><td>指定缩进级别,以美化输出的 <code>JSON</code> 数据,使其更具可读性,仅当 <code>format_json</code> 为 <code>True</code> 时有效。</td><td>4</td></tr><tr><td><code>ensure_ascii</code></td><td><code>bool</code></td><td>控制是否将非 <code>ASCII</code> 字符转义为 <code>Unicode</code>。设置为 <code>True</code> 时,所有非 <code>ASCII</code> 字符将被转义;<code>False</code> 则保留原始字符,仅当<code>format_json</code>为<code>True</code>时有效。</td><td><code>False</code></td></tr><tr><td><code>save_to_img()</code></td><td>将结果保存为图像格式的文件</td><td><code>save_path</code></td><td><code>str</code></td><td>保存的文件路径,支持目录或文件路径。</td><td>无</td></tr></table><ul> <li>调用<code>print()</code> 方法会将结果打印到终端,打印到终端的内容解释如下: <ul> <li><code>input_path</code>: <code>(str)</code> 待预测图像的输入路径</li> <li><code>page_index</code>: <code>(Union[int, None])</code> 如果输入是PDF文件,则表示当前是PDF的第几页,否则为 <code>None</code></li> <li><code>model_settings</code>: <code>(Dict[str, bool])</code> 配置产线所需的模型参数 <ul> <li><code>use_doc_preprocessor</code>: <code>(bool)</code> 控制是否启用文档预处理子产线</li> <li><code>use_textline_orientation</code>: <code>(bool)</code> 控制是否启用文本行方向分类功能</li> </ul> </li> <li><code>doc_preprocessor_res</code>: <code>(Dict[str, Union[str, Dict[str, bool], int]])</code> 文档预处理子产线的输出结果。仅当<code>use_doc_preprocessor=True</code>时存在 <ul> <li><code>input_path</code>: <code>(Union[str, None])</code> 图像预处理子产线接受的图像路径,当输入为<code>numpy.ndarray</code>时,保存为<code>None</code></li> <li><code>model_settings</code>: <code>(Dict)</code> 预处理子产线的模型配置参数 <ul> <li><code>use_doc_orientation_classify</code>: <code>(bool)</code> 控制是否启用文档方向分类</li> <li><code>use_doc_unwarping</code>: <code>(bool)</code> 控制是否启用文本图像矫正</li> </ul> </li> <li><code>angle</code>: <code>(int)</code> 文档方向分类的预测结果。启用时取值为[0,1,2,3],分别对应[0°,90°,180°,270°];未启用时为-1</li> </ul> </li> <li><code>dt_polys</code>: <code>(List[numpy.ndarray])</code> 文本检测的多边形框列表。每个检测框由4个顶点坐标构成的numpy数组表示,数组shape为(4, 2),数据类型为int16</li> <li><code>dt_scores</code>: <code>(List[float])</code> 文本检测框的置信度列表</li> <li><code>text_det_params</code>: <code>(Dict[str, Dict[str, int, float]])</code> 文本检测模块的配置参数 <ul> <li><code>limit_side_len</code>: <code>(int)</code> 图像预处理时的边长限制值</li> <li><code>limit_type</code>: <code>(str)</code> 边长限制的处理方式</li> <li><code>thresh</code>: <code>(float)</code> 文本像素分类的置信度阈值</li> <li><code>box_thresh</code>: <code>(float)</code> 文本检测框的置信度阈值</li> <li><code>unclip_ratio</code>: <code>(float)</code> 文本检测框的膨胀系数</li> <li><code>text_type</code>: <code>(str)</code> 文本检测的类型,当前固定为"general"</li> </ul> </li> <li><code>textline_orientation_angles</code>: <code>(List[int])</code> 文本行方向分类的预测结果。启用时返回实际角度值(如[0,0,1]),未启用时返回[-1,-1,-1]</li> <li><code>text_rec_score_thresh</code>: <code>(float)</code> 文本识别结果的过滤阈值</li> <li><code>rec_texts</code>: <code>(List[str])</code> 文本识别结果列表,仅包含置信度超过<code>text_rec_score_thresh</code>的文本</li> <li><code>rec_scores</code>: <code>(List[float])</code> 文本识别的置信度列表,已按<code>text_rec_score_thresh</code>过滤</li> <li><code>rec_polys</code>: <code>(List[numpy.ndarray])</code> 经过置信度过滤的文本检测框列表,格式同<code>dt_polys</code></li> <li><code>rec_boxes</code>: <code>(numpy.ndarray)</code> 检测框的矩形边界框数组,shape为(n, 4),dtype为int16。每一行表示一个矩形框的[x_min, y_min, x_max, y_max]坐标,其中(x_min, y_min)为左上角坐标,(x_max, y_max)为右下角坐标</li> </ul> </li> <li>调用<code>save_to_json()</code> 方法会将上述内容保存到指定的<code>save_path</code>中,如果指定为目录,则保存的路径为<code>save_path/{your_img_basename}_res.json</code>,如果指定为文件,则直接保存到该文件中。由于json文件不支持保存numpy数组,因此会将其中的<code>numpy.array</code>类型转换为列表形式。</li> <li>调用<code>save_to_img()</code> 方法会将可视化结果保存到指定的<code>save_path</code>中,如果指定为目录,则保存的路径为<code>save_path/{your_img_basename}_ocr_res_img.{your_img_extension}</code>,如果指定为文件,则直接保存到该文件中。(产线通常包含较多结果图片,不建议直接指定为具体的文件路径,否则多张图会被覆盖,仅保留最后一张图)</li></ul><p>此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:</p><table><thead><tr><th>属性</th><th>属性说明</th></tr></thead><tr><td rowspan="1"><code>json</code></td><td rowspan="1">获取预测的 <code>json</code> 格式的结果</td></tr><tr><td rowspan="2"><code>img</code></td><td rowspan="2">获取格式为 <code>dict</code> 的可视化图像</td></tr></table><ul> <li><code>json</code> 属性获取的预测结果为dict类型的数据,相关内容与调用 <code>save_to_json()</code> 方法保存的内容一致。</li> <li><code>img</code> 属性返回的预测结果是一个字典类型的数据。其中,键分别为 <code>ocr_res_img</code> 和 <code>preprocessed_img</code>,对应的值是两个 <code>Image.Image</code> 对象:一个用于显示 OCR 结果的可视化图像,另一个用于展示图像预处理的可视化图像。如果没有使用图像预处理子模块,则字典中只包含 <code>ocr_res_img</code>。</li></ul></details># 五、部署与二次开发* **多系统支持**:兼容Windows、Linux、Mac等主流操作系统。* **多硬件支持**:除了英伟达GPU外,还支持Intel CPU、昆仑芯、昇腾等新硬件推理和部署。* **高性能推理插件**:推荐结合高性能推理插件进一步提升推理速度,详见[高性能推理指南](https://github.com/PaddlePaddle/PaddleOCR/blob/release/3.0/docs/version3.x/deployment/high_performance_inference.md)。* **服务化部署**:支持高稳定性服务化部署方案,详见[服务化部署指南](https://github.com/PaddlePaddle/PaddleOCR/blob/release/3.0/docs/version3.x/deployment/serving.md)。* **二次开发能力**:支持自定义数据集训练、字典扩展、模型微调。举例:如需增加韩文识别,可扩展字典并微调模型,无缝集成到现有产线,详见[文本检测模块使用教程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/3.0/docs/version3.x/module_usage/text_detection.md)及[文本识别模块使用教程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/3.0/docs/version3.x/module_usage/text_recognition.md)